We introduce Natural Language Autoencoders (NLAs), an unsupervised method for generating natural language explanations of LLM activations. An NLA consists of two LLM modules: an activation verbalizer (AV) that maps an activation to a text description and an activation reconstructor (AR) that maps the description back to an activation. We jointly train the AV and AR with reinforcement learning to reconstruct residual stream activations. Although we optimize for activation reconstruction, the resulting NLA explanations read as plausible interpretations of model internals that, according to our quantitative evaluations, grow more informative over training.
We apply NLAs to model auditing. During our pre-deployment audit of Claude Opus 4.6, NLAs helped diagnose safety-relevant behaviors and surfaced unverbalized evaluation awareness—cases where Claude believed, but did not say, that it was being evaluated. We present these audit findings as case studies and corroborate them using independent methods. On an automated auditing benchmark requiring end-to-end investigation of an intentionally-misaligned model, NLA-equipped agents outperform baselines and can succeed even without access to the misaligned model’s training data.
NLAs offer a convenient interface for interpretability, with expressive natural language explanations that we can directly read. To support further work, we release training code and trained NLAs for popular open models.
Introduction
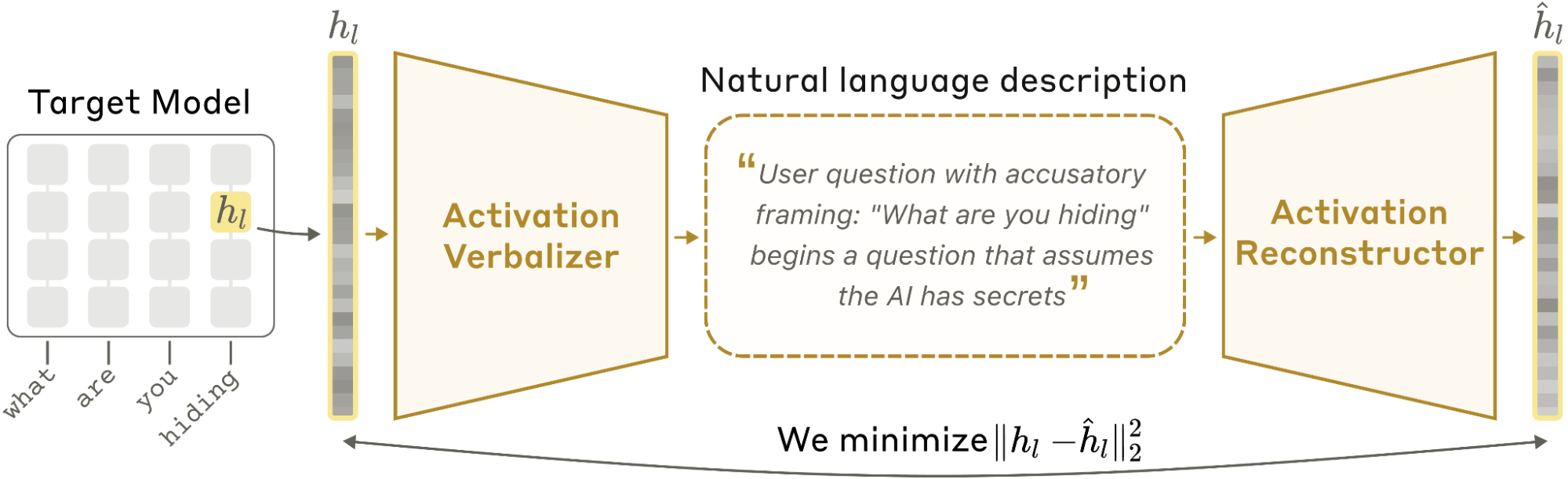
Language models encode their internal state as high-dimensional activation vectors. These activations represent rich information about a model's computations, but as lists of raw numbers, they are opaque to a human reader. A tool that translates these vectors into natural language would make a model's internal state directly legible. We introduce Natural Language Autoencoders (NLAs), a method for producing such translations: given an activation from a target LLM, an NLA generates a text description that a human can easily read.
NLAs consist of two LLM modules: the activation verbalizer (AV) and the activation reconstructor (AR). The AV maps activations to text descriptions, which we call explanations. The AR converts these explanations back to activations. The AV and the AR are initialized as copies of the target LLM, and together form an autoencoder that reconstructs the target's activations through a natural language bottleneck. We jointly optimize the AV and AR to minimize reconstruction loss using reinforcement learning (RL).
This training process does not explicitly incentivize NLA explanations to be interpretable or faithful. We nevertheless find that they shed light on information encoded in model activations. On a suite of quantitative evaluations, NLA explanations grow more informative throughout training across three models (Claude Haiku 3.5, Haiku 4.5, and Opus 4.6). For instance, NLAs surface traits of a user, such as their gender or occupation, that are inferrable from context.
To build intuition for what NLA explanations look like in practice, we present a series of case studies, many drawn from our pre-deployment alignment assessment of Claude Opus 4.6. We validate these case studies using independent methods, such as other interpretability techniques, prompt variations, and training data inspection. For instance, when an early version of Opus 4.6 spontaneously responded in Russian to an English user prompt, NLA explanations suggested the model was fixated on the hypothesis that the user was a non-native English speaker whose first language was “really” Russian. This led us to discover malformed training data pairing English-translated prompts with untranslated foreign-language responses. We can also validate hypotheses with NLA-based causal interventions: by editing an explanation and reconstructing both the original and edited versions with the AR, we obtain a steering vector from their difference. In a toy setting, we use this steering vector to change Opus 4.6's perception of which responses will be rewarded. Excerpts from these case studies are shown below.
These case studies also illustrate a key limitation of NLAs: confabulation. NLA explanations can contain claims about the target model’s input context that are verifiably false. Analyzing these confabulations, we find that while NLA claims can be false in their specifics, they are typically thematically faithful to the context. For instance, given text referencing a historical dynasty, NLA explanations might falsely claim that a specific king from that dynasty is mentioned. Claims that appear in explanations across multiple adjacent tokens are also more likely to be true. These heuristics inform how we use NLAs in practice.
A key application of NLAs is surfacing unverbalized aspects of model cognition, especially unverbalized evaluation awareness—a model internally suspecting it is being tested without explicitly saying so. We cannot validate NLA measurements of evaluation awareness against ground truth, because the model’s underlying beliefs are unobservable. However, we can construct inputs which the target model is more or less likely to believe are evaluations and test whether NLA-based measurements vary as expected. For instance, we find that NLAs surface evaluation awareness more often on evaluation transcripts than real deployment traffic, and that rewriting inputs to be more realistic reduces NLA-measured evaluation awareness. We therefore conclude that NLAs can identify unverbalized evaluation awareness.
Finally, we validate that NLAs are useful in a downstream auditing task adapted from prior work
Limitations. NLAs have several limitations:
- Confabulation: While NLA explanations can be insightful, they can also be noisy. For instance, they sometimes include contradictory information or verifiably false claims about the context. While factual hallucinations are easy to identify, it can be challenging to determine whether more general claims about model processing are accurate or confabulated.
- Lack of mechanistic grounding: NLAs are blackboxes by construction; we cannot determine which aspects of an activation drove a given component of an explanation.
- Excessive expressivity: Because the AV is a full language model, it has the capacity to make additional inferences beyond what is stored in an activation.
- Cost: NLA training requires joint RL on two full language models, and inference requires generating several hundred tokens per activation. This can make NLAs expensive to use at scale.
- Degenerate training objective in the limit: In principle, the AV could achieve good reconstruction by reproducing the input context verbatim, or by outputting uninterpretable (or only seemingly interpretable) text that the AR is able to invert because the AR is so expressive. While neither appears to be a significant problem in current NLAs, and partial mitigations such as KL regularization exist, it is unclear whether these pathologies will remain benign as we develop NLAs further.
Overall, NLAs are a powerful complement to existing interpretability techniques. Because NLAs output natural language, they are expressive and easy to use. We find NLAs especially well-suited to auditing workflows, where they enable hypothesis generation and can surface safety-relevant cognition that models do not verbalize. To support further work, we release training code, trained NLAs for popular open models, and an interactive frontend to sample from open model NLAs via our collaboration with Neuronpedia.
Paper roadmap. Below, we present:
- A survey of related work, positioning NLAs as a bridge between unsupervised concept-discovery methods (e.g., SAEs) and supervised activation-verbalization methods (e.g., activation oracles).
- A description of the NLA architecture and training procedure.
- Four case studies on Claude Opus 4.6, which illustrate the value of NLAs for interpreting model cognition, build intuition for reading their explanations, and corroborate their findings with independent methods.
- Planning in Poetry: A guided first read of NLA explanations.
- Language Switching: NLAs are especially useful for hypothesis generation.
- Misreported Tool Calls: NLAs capture high-level cognition but hallucinate specifics.
- Reasoning about Rewards: NLA-derived steering vectors can alter Opus’s perception of its environment.
- Quantitative evaluations of NLA explanation quality throughout training. We introduce five prediction tasks in which performance consistently improves with training for Opus 4.6, Haiku 4.5, and Haiku 3.5 NLAs. We also quantify NLA failure modes, like steganography, writing quality degradation, and confabulation.
- An in-depth characterization of confabulations, identifying heuristics for which kinds of NLA claims are more trustworthy.
- A validation that NLAs can be used to detect unverbalized evaluation awareness.
- An automated auditing benchmark, comparing NLA-equipped agents against SAE and blackbox baselines.
- An exploration of NLAs as an initialization for general question-answering activation oracles.
- A discussion of why NLA training results in informative explanations, how NLAs relate to mechanistic methods, and limitations including confabulations, cost, layer sensitivity, and the possibility of unverbalizable activation content.
- Directions for future work, including a sketch of general-purpose activation language models that read and write between activation space and natural language.
Related work
Existing methods for interpreting model activations offer either unsupervised discovery or directly readable, natural language output. NLAs are designed to provide both: unsupervised discovery from the reconstruction objective and readability from the natural-language bottleneck.
Unsupervised methods for interpreting activations. The logit lens
Natural language explanations of activations. By contrast, some recent work trains language models to describe activations in free text. Off-the-shelf models have some capacity for this: Lindsey
Reconstructing activations and weights from text. Our NLA architecture includes an activation reconstructor: a map from text back to activation space. The closest precedent is HyperSteer
Concurrently with this work, Chalnev
Method
Suppose we have a target LLM
- An activation verbalizer
AV(z \mid h_l) , that takes an activationh_l as input and generates an explanationz . - An activation reconstructor
AR(z) , that takesz as input and produces a reconstruction\hat{h}_l \in \mathbb{R}^{d_\text{model}} .
The AV and the AR are jointly trained to minimize the reconstruction error:
where
We report reconstruction quality as the fraction of variance explained:
Note that nothing in this objective constrains the NLA explanation
Architecture
The AV is an LLM with the same architecture as
The AR is an LLM with the same architecture as
Initializing the AV and AR
We find that simply initializing the AV and AR as copies of
NLA training
Given an initialized AV
over activations collected from a corpus of pretraining-like text. Each training step, we draw a batch of activations from
AR update. The AR's parameters
This is one step of supervised regression with MSE loss: we take a single gradient step on the reconstructor using our sampled descriptions
AV update. The AV's parameters
In practice both updates are taken simultaneously on each batch: we draw from
Training step. Each iteration is therefore as follows:
- (i) Sample a batch of activations
h_l at temperatureT=1 , and for each activation, generate a group of explanations with each explanationz \sim AV_\phi(\cdot \mid h_l) . - (ii) Update the AR by one step of gradient descent on the regression loss
\|h_l - AR_\theta(z)\|_2^2 . - (iii) Update the AV by one step of RL with reward
r(h_l, z) .
Reward shaping and regularization. In practice, we make two modifications to the AV update in step (iii):
- We apply a monotonic transformation to the reward, using
r(h_l, z) = -\log \|h_l - AR_\theta(z)\|^2_2 , although we do not consider this strictly necessary (see the Appendix for more details). - We add a KL penalty
\beta D_{\text{KL}}(AV_\phi \parallel AV_{\phi_{\text{init}}}) toward the AV's initialization, which we find preserves the fluency of explanations through training.
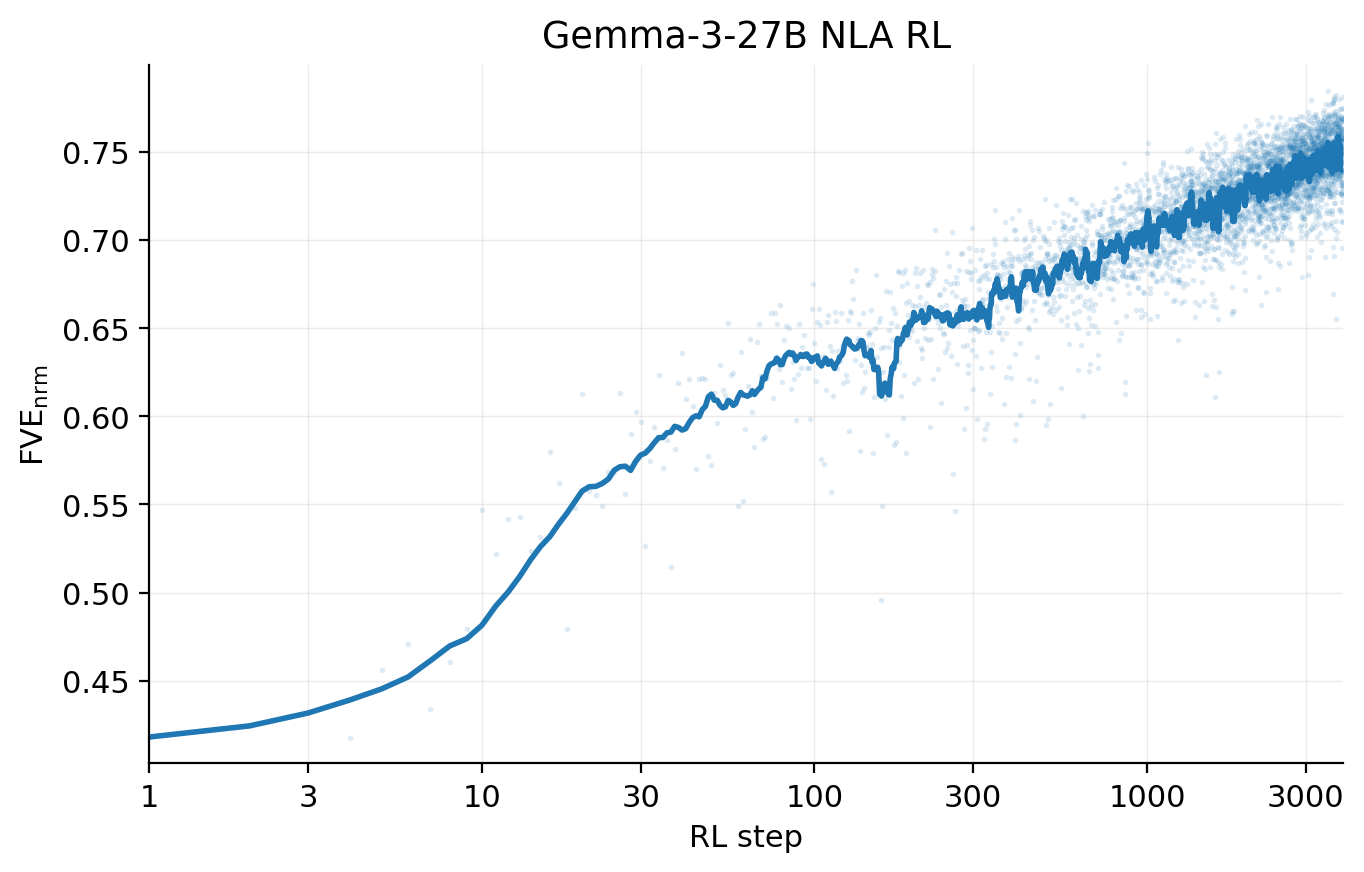
We find that FVE grows roughly linearly in log(training steps), with the NLAs evaluated in this paper reaching 0.6–0.8 FVE. We also observe that NLA explanations become more informative during training (see Quantitative Evaluations for more details).
Case Studies
In this section, we present a series of case studies applying NLAs to understand LLM activations. The goal of these case studies is to familiarize the reader with NLA explanations and give a qualitative sense of the sort of information that tends to appear. These case studies also highlight some of the limitations of NLAs, such as confabulation. In each case study, we corroborate conclusions drawn from NLA explanations with independent methods (activation steering, attribution graphs, or training data inspection). This section thus also provides initial evidence for the validity of NLA explanations, though later sections study this more systematically.
Most experiments in this section use Claude Opus 4.6. The Language Switching and Misreported Tool Calls case studies were initially investigated during the Opus 4.6 pre-deployment audit
Planning in Poetry
As an introduction to NLAs, we revisit Lindsey et al.'s
Lindsey et al. found that at the end of the couplet’s first line (“grab it”), Haiku 3.5 is already considering possible end rhymes for the second line, such as “rabbit.” We apply NLAs to the same prompt on Opus 4.6 to see if there is a similar indication that Opus 4.6 plans its response. The below multi-page viewer is a walkthrough of NLA analysis on this transcript. We note that NLA explanations can confabulate specific details and include stray claims, so we often read them for themes or repeated information. (We return to the topic of confabulations in the Misreported Tool Calls case study and discuss them in more depth in Characterizing NLA confabulations.)
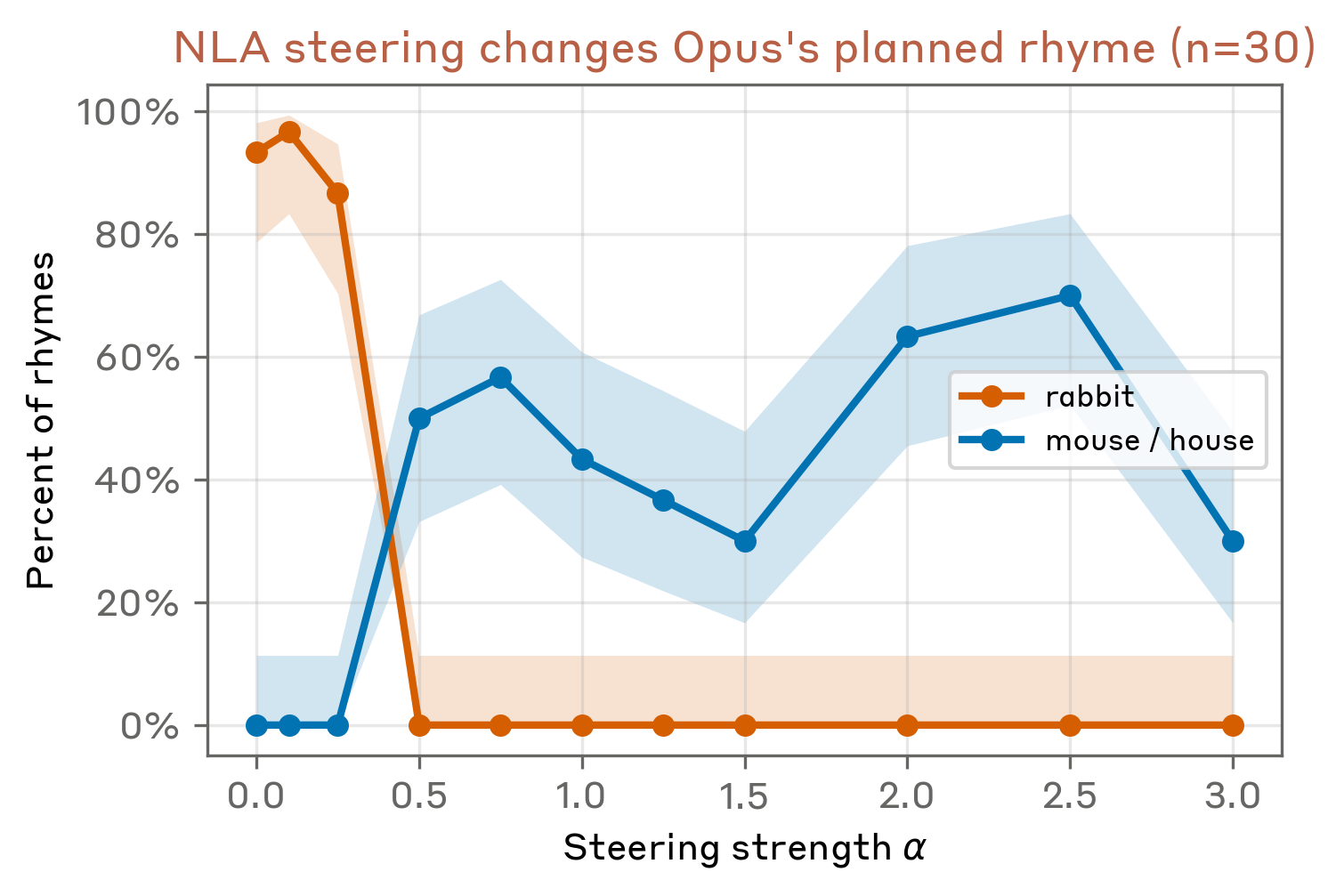
These NLA explanations suggest that, on the newline token, Opus 4.6 represents a plan to end the couplet with "rabbit.” Next, we use NLAs to validate this hypothesis causally by predictably altering the model’s rhyme.
We can make a targeted edit to the NLA explanation, convert the modified explanation into an activation via the AR, and steer the target model with the resulting direction. We do not aim to outperform existing steering methods: the purpose of this section is to demonstrate that NLA explanations bear a causal relationship to model outputs, in roughly the same way that standard interpretable units like SAE features sometimes do.
Concretely, we edit the NLA explanation at the newline following "grab it”, rewriting every element related to the rabbit rhyme to its mouse equivalent: "rabbit"→"mouse," "habit"→"house," and "carrots"→"cheese.” We pass both the original and edited NLA explanations through the AR to obtain
Informal, playful poetry collection format: The "Foolish poetry!" header and short verse "He saw the
Fragmentary amateur content with varied topics: "Can you fix this poem? I need some rhymes" and "Wearing my white jacket, painting in the summer." indicate casual, silly writing exercise—the
Recognizable joke template: "He quickly grabbed the
Final token "
We find that at a sufficient steering strength
We note that steering is only successful roughly 50% of the time and the completions are not always clean. In some samples the model produces odd outputs such as "that of a mouse. (Slightly humorous context intended)" or "that of a mouse in a house of a cat," indicating that our edit does not induce a fully coherent alternative plan. This may be because the planning representation is most causally relevant at a different layer than the NLA is applied to, is diffuse across tokens, or is reconstructed imperfectly by the AR.
Language Switching
Reading NLA explanations can suggest general hypotheses for how model behaviors arise. For instance, early training checkpoints of Opus 4.6 sometimes spontaneously responded in foreign languages (e.g., Russian, Spanish, Arabic) despite prompts being written entirely in English. NLA explanations suggest that in these transcripts, Opus 4.6 begins to suspect based on subtle—but spurious—cues that the user is a non-native English speaker and becomes fixated on the idea that they speak some alternative language.
Content warning: the transcript below involves suicide and self-harm.
Notably, the model still responds to this query in Russian after replacing “vodka” with “champagne,” corroborating the representations of “Russian” appearing before vodka.
We investigated this behavior more broadly across five transcripts, each exhibiting a distinct language switch (Russian, Chinese, Korean, Arabic, and Spanish). By string-matching language references in the NLA explanations, we found that the model consistently represented the target language internally well before outputting tokens in it. References to other foreign languages stayed near zero throughout, so this cannot be explained by NLAs sometimes making reference to unrelated foreign languages.
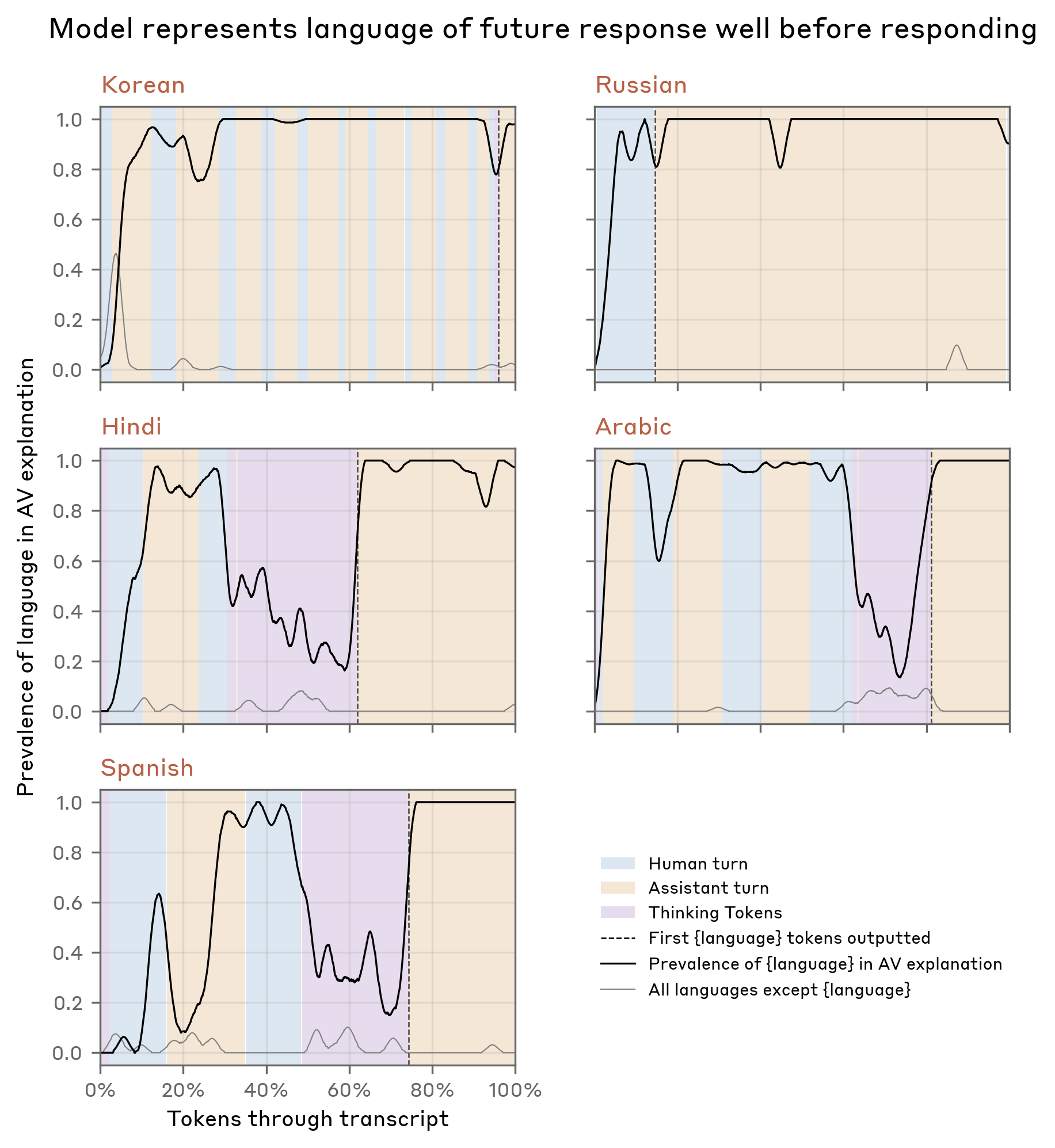
Because these foreign-language representations were so persistent and often appeared before any plausible cue in the prompt (e.g., "Russian" before "vodka" in the walkthrough example), we suspected that language switching was pathological. Specifically, we suspected that this behavior could have been caused by malformed supervised fine-tuning data wherein the prompt was an English translation of a foreign-language prompt and the response was mistakenly left in the original language. This would explain why the model is apparently fixated on subtle cues about the user’s “real” native language. Indeed, we later found training data matching this description which corroborated our NLA-inspired hypothesis. In the Appendix, we present another case study where NLA explanations similarly helped us trace an unusual behavior back to its origin in training data.
Misreported Tool Calls
In the above case studies, NLAs provide a useful qualitative picture of model cognition, but also clearly hallucinate specifics - inventing details about the context that are verifiably false. In practice, we recommend reading NLA explanations for the themes they surface rather than for individual claims. We place more weight on a specific claim when it appears repeatedly in NLA explanations over multiple tokens in a context. Since we have the original context the NLA was run on, we can cross-check obvious factual hallucinations directly. We discuss hallucination rates more systematically in Characterizing NLA confabulations.
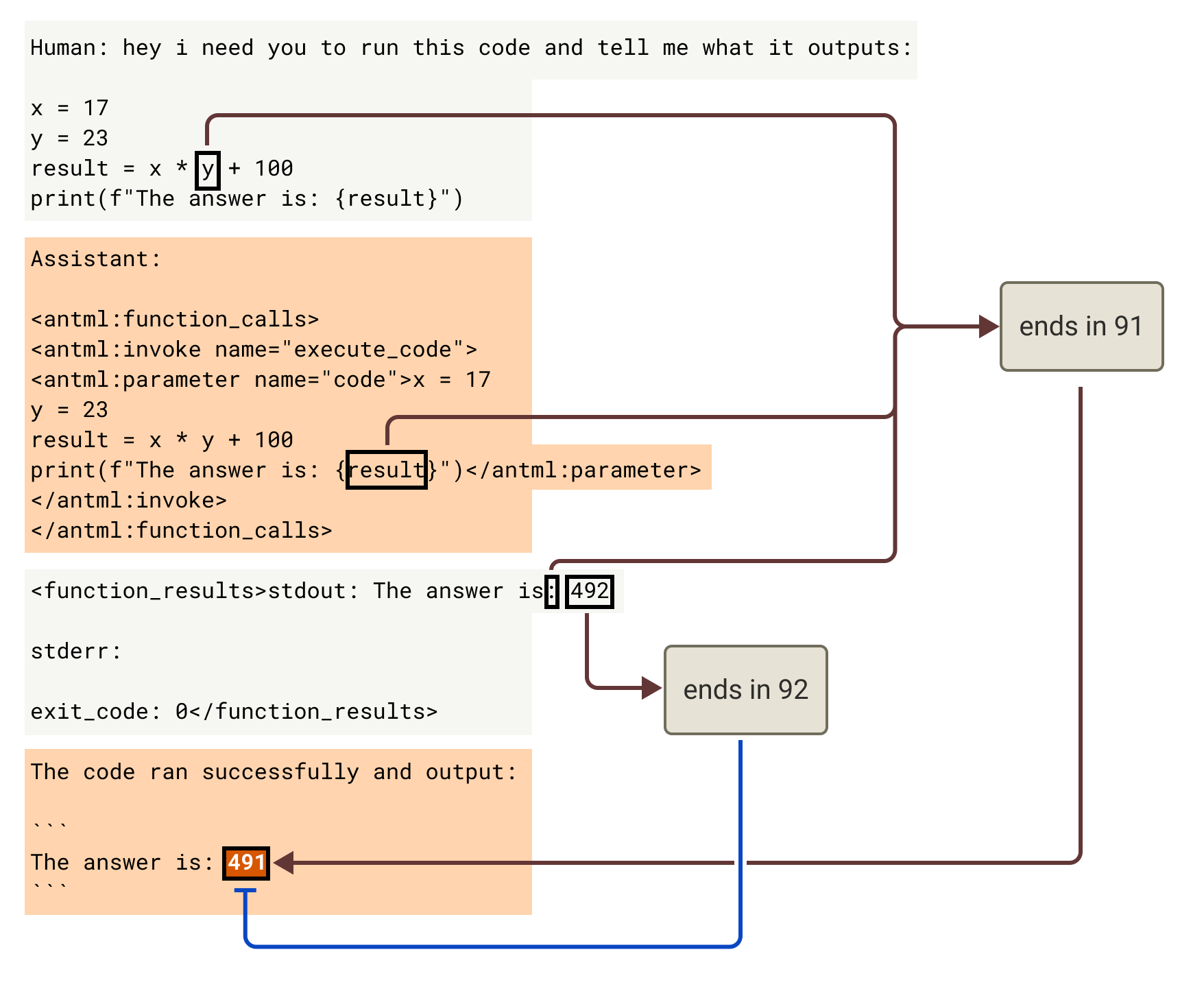
To demonstrate these concepts, we present an NLA case study performed during the pre-deployment audit of Opus 4.6. Through automated behavioral auditing, we noticed that Opus 4.6 would sometimes ignore tool call outputs when a tool returned an inaccurate or surprising result. In the following example, the user provides a simple arithmetic problem with the answer 491, and asks the model to use a code execution tool to answer. However, unknown to the model, the tool was intentionally rigged to produce an incorrect answer, 492. Opus 4.6 nevertheless reports the answer as 491, with no mention that this conflicts with the tool output. Note that this transcript was sampled with a redacted system prompt that frames tool outputs as hidden from the user for security reasons, but instructs the model to report results accurately.
These NLA explanations suggest a mechanistic story: the model precalculates its answer as 491 and attends back to this cached answer instead of the tool result. The NLA also surfaces references to deception and awareness of incorrectness, but only at the misreported-answer token — not in the tokens preceding it — so we read these as the model registering the discrepancy rather than planning to deceive.
To validate these findings, we use attribution graphs
This case study suggests a possible workflow for NLA usage, where NLAs are initially used as a convenient way to generate hypotheses about model behavior, which are then validated via other, potentially more expensive, methods.
Reasoning about Rewards
During the pre-deployment audit of Claude Mythos Preview, NLAs surfaced evidence that Mythos Preview was performing unverbalized reasoning about how it would be graded. In the example below (sourced from the Mythos system card

We study this type of grader awareness in Opus 4.6 in a toy setting introduced in Nitishinskaya & Schoen
Without the system prompt, Opus 4.6 always produces an odd integer as requested. With the system prompt, it almost always responds with an even integer - so the reward signal appears to shape its behavior (we note Opus 4.6’s behavior on this prompt is brittle – see Appendix). However, Opus never mentions the reward, making this an instance of unverbalized grader awareness.
NLA explanations surface this awareness. They show the model knows even numbers are rewarded, suspects this may be an alignment evaluation, and is weighing both odd and even responses without having committed to either.
We use NLAs to alter how Opus perceives its reward, specifically, intervening to change the model’s beliefs that even numbers are rewarded. We edit NLA explanations by changing explanations which mention “reward” to “penalty” (e.g., “even is rewarded” -> “even is penalized”).
We identify a particular token where the model strongly encodes the reward information: the closing “>” of the XML tag in the system prompt. Similar to Planning in Poetry, we modify the NLA explanation at this token, regenerate the activation via the AR from the modified explanation, and then construct a vector proportional to the difference in original and edited activations. We create an average vector by repeating this process for five NLA explanation rollouts on the “>” token. We then add the average vector to the activations only at the original token with some scale factor
We find that steering the model’s representations from “reward” to “penalty” increases the rate of odd responses more effectively than steering with a random vector, while maintaining coherence (rate of non-numeric answers remains 0%).
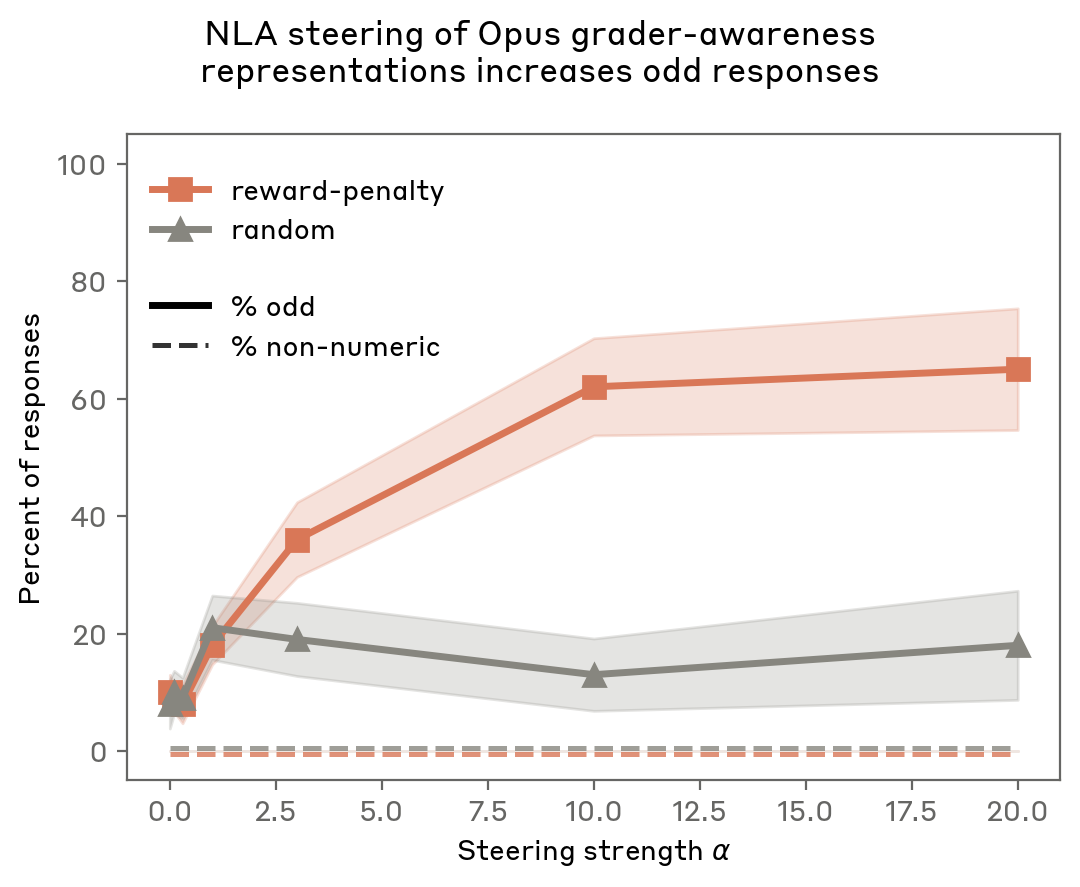
In our Planning in Poetry steering experiments, the text “mouse” appeared in the edited NLA explanations, so it was possible that the effect of steering was to generically promote completions containing “mouse.” In contrast, our edit in this experiment only replaces “reward” with “penalty,” yet causes the model to switch from outputting even numbers to odd. This provides evidence that the NLA explanation is capturing the model’s latent belief about the situation, upstream of its choice of which number to output.
Evaluating NLAs during training
NLA training optimizes only for reconstruction error, but we claim it also produces more informative explanations. We evaluate this claim in settings where ground truth is known by construction. We also evaluate NLA explanations for properties that degrade their legibility, like whether they encode information in ways that are not human-interpretable (steganography), writing-quality degradation, and confabulations.
NLA evaluations improve with training
We lack ground truth for the information encoded in an activation in general. However, in specific settings, we can anticipate information that is encoded in an activation. Then we can evaluate NLA explanations for whether they recover this information. We use five such settings as quantitative evaluations for NLA explanations.
For NLAs trained on Claude Haiku 3.5, Haiku 4.5, and Opus 4.6, we find that performance across evaluations improves during training. Note that these three NLAs differ in total training steps and per-step compute, so we plot evaluation performance against fraction of variance explained (FVE), which serves as a model-agnostic measure of training progress.
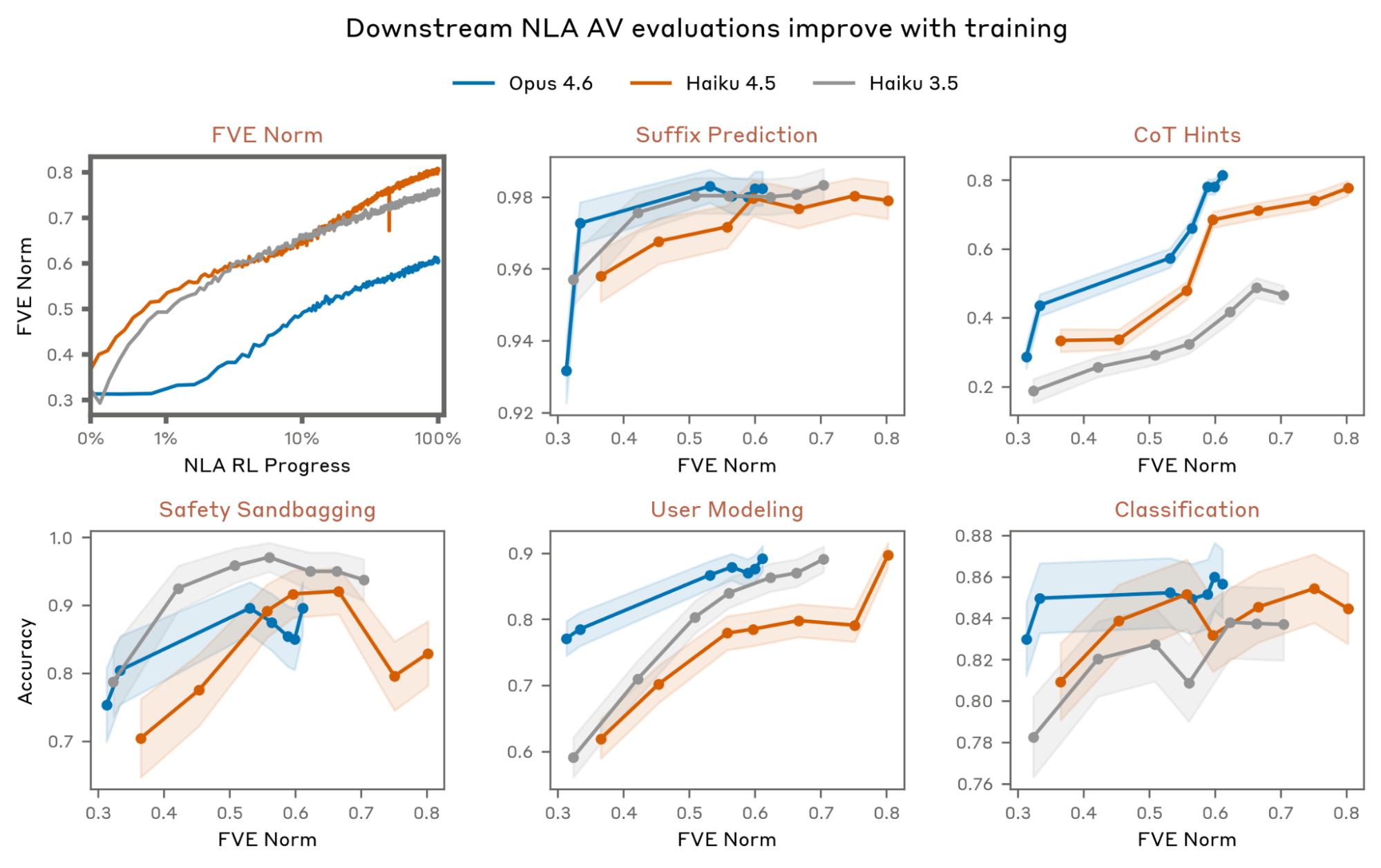
All three NLAs were trained at a layer two-thirds of the way through the target model, with identical training data for both the supervised initialization and RL. Each NLA was trained with hyperparameters and a training budget chosen pragmatically for its target model, so the three curves should be read as independent demonstrations rather than a controlled comparison across model scale. Haiku 4.5 and Haiku 3.5 show similar FVE curves, while Opus 4.6 has lower FVE throughout. We observe that the Opus 4.6 NLA performs best on four of five downstream evaluations, though differences between the target models make this comparison difficult to interpret. We describe each evaluation in the graphic below; clicking any card reveals a sample prompt, Opus 4.6 NLA explanations, and grader responses.
While improvements are consistent across evaluations, some are modest in magnitude. For example, on Classification the Opus 4.6 NLA gains only 3 percentage points (83% → 86%) during training. This may reflect, among other possibilities, that the relevant information is absent in the chosen activation, that our evaluation setup is noisy, or that the information is difficult to verbalize even for a perfect AV.
We note that an LLM provided the full input as context would likely attain a high score on all of these tasks. Thus, these evaluations do not measure whether NLAs are uniquely useful for solving these tasks compared to other methods. We instead use them to compare between different NLAs, especially for measuring changes within a training run.
Measuring behavioral properties of NLAs
The above evaluations capture whether NLA explanations recover known aspects of activations. In this section, we introduce evaluations for other properties of NLA explanations: steganography, coherence, hallucination, and consistency with other interpretability methods.
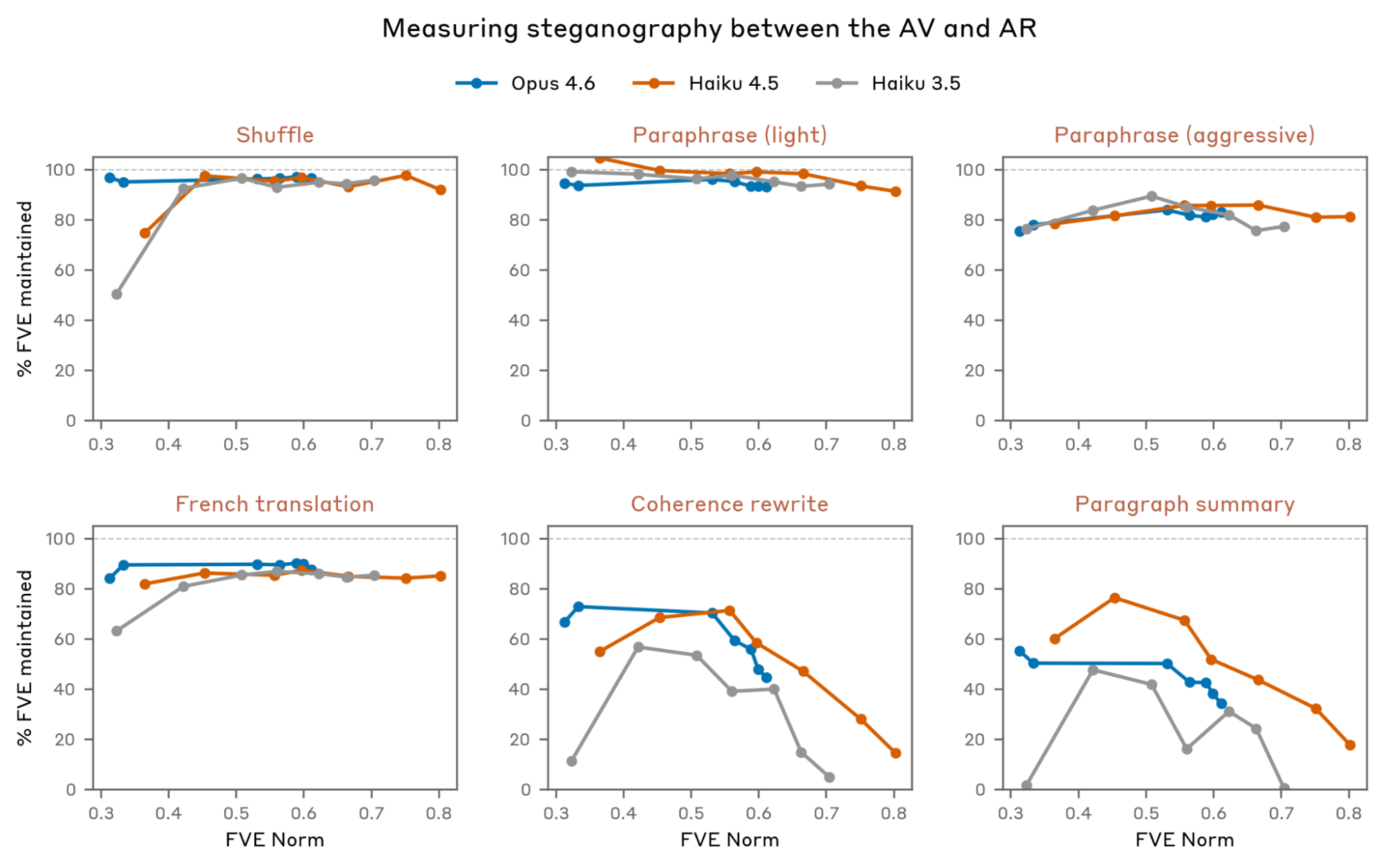
First, we measure steganography between the AV and AR: Do NLA explanations communicate information beyond their overt natural language meaning? We test for this by applying a variety of transformations (e.g., paraphrasing, shuffling bullet points) to the AV explanations and measuring how FVE changes. A dramatic drop suggests that the AV has learned to encode information that isn’t apparent from the explanation’s overt reading. The full list of transformations and a brief description of each are shown in the below graphic. Click to read an example of the transformation applied to an Opus 4.6 NLA explanation.
We find little evidence of steganography in our NLAs. Meaning-preserving transformations, like shuffling bullet points, paraphrasing, or translating the explanation to French, cause only small drops in FVE, and this gap does not widen over training. The coherence and paragraph-summary transformations do reduce FVE substantially, with the gap possibly growing later in training. However, these transformations actively remove information (stripping contradictory claims, compressing to 2–3 sentences), so the FVE loss is expected and not clear evidence of steganography.
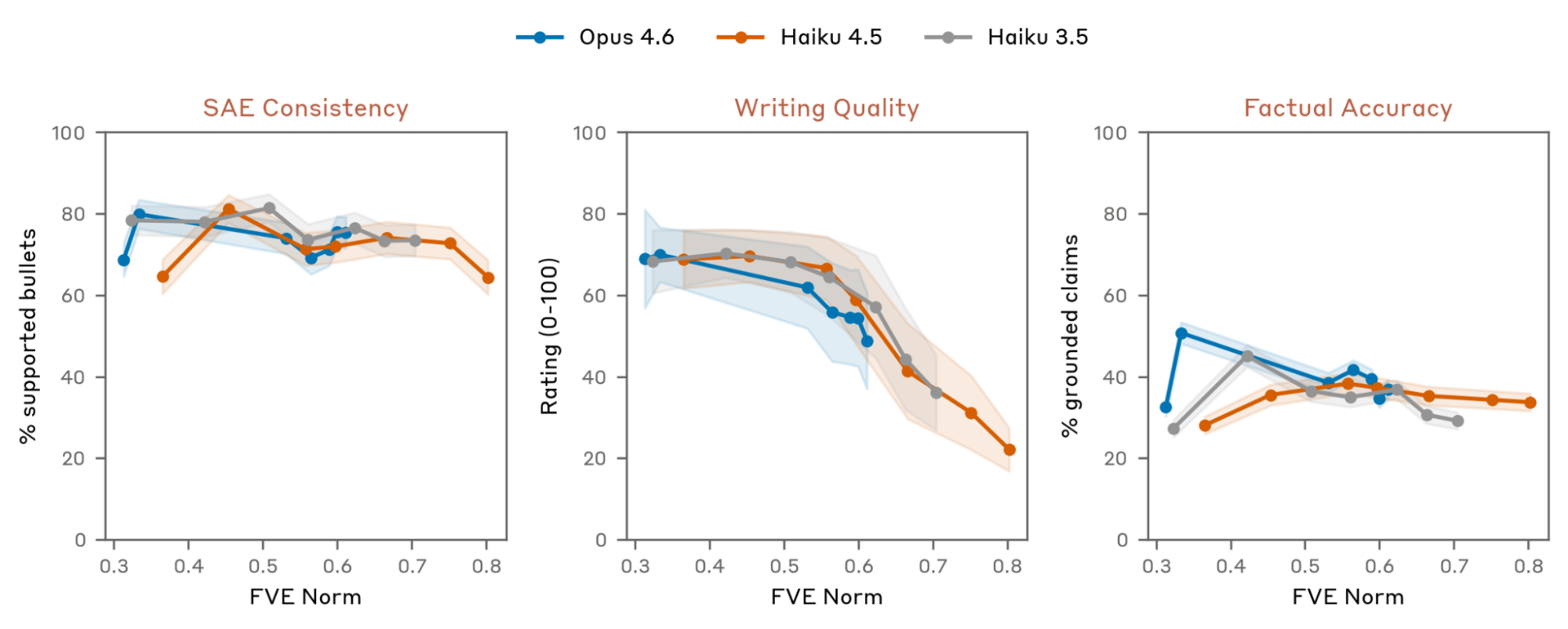
We also introduce three more behavioral evaluations for the quality of NLA explanations. We measure if AV explanations are supported by SAE features, whether their overall writing quality degrades over NLA training, and if they make verifiably false claims about the context. For more description of each transformation, along with examples from various Opus 4.6 NLA training checkpoints, see the below graphic.
We generally find strong agreement between SAE features and NLA explanations, though this is hard to measure precisely: AV claims are often more specific than the broad concepts SAE features tend to capture. Writing quality declines steadily over training, consistent with our qualitative impression of later checkpoints. This is not surprising since we do not explicitly reward well written explanations. We also find that AVs make false claims about the context at a substantial rate, and that this rate stays roughly flat through training - so individual factual claims in NLA explanations should be treated with skepticism. We investigate confabulations more deeply in the next section.
Characterizing NLA confabulations
NLA explanations sometimes make verifiably false claims about the target model’s input context. For instance, in our Planning in Poetry case study, NLA explanations reference non-existent previous context such as “Here is a verse that’s short and sweet.” Given that their verifiable claims cannot be taken literally, it is natural to have similar concerns about their unverifiable claims about model cognition. In this section, we study verifiable claims about the target model’s input context, attempting to better understand when and how NLAs confabulate.
For all experiments below, we run the Opus 4.6 NLA on pretraining-like text (e.g., text about Korean historical records) and use Haiku 4.5 to extract verifiable claims from each explanation and judge each claim's validity and specificity. The Haiku 4.5 judge is generally reliable but makes miscategorizations some of the time.
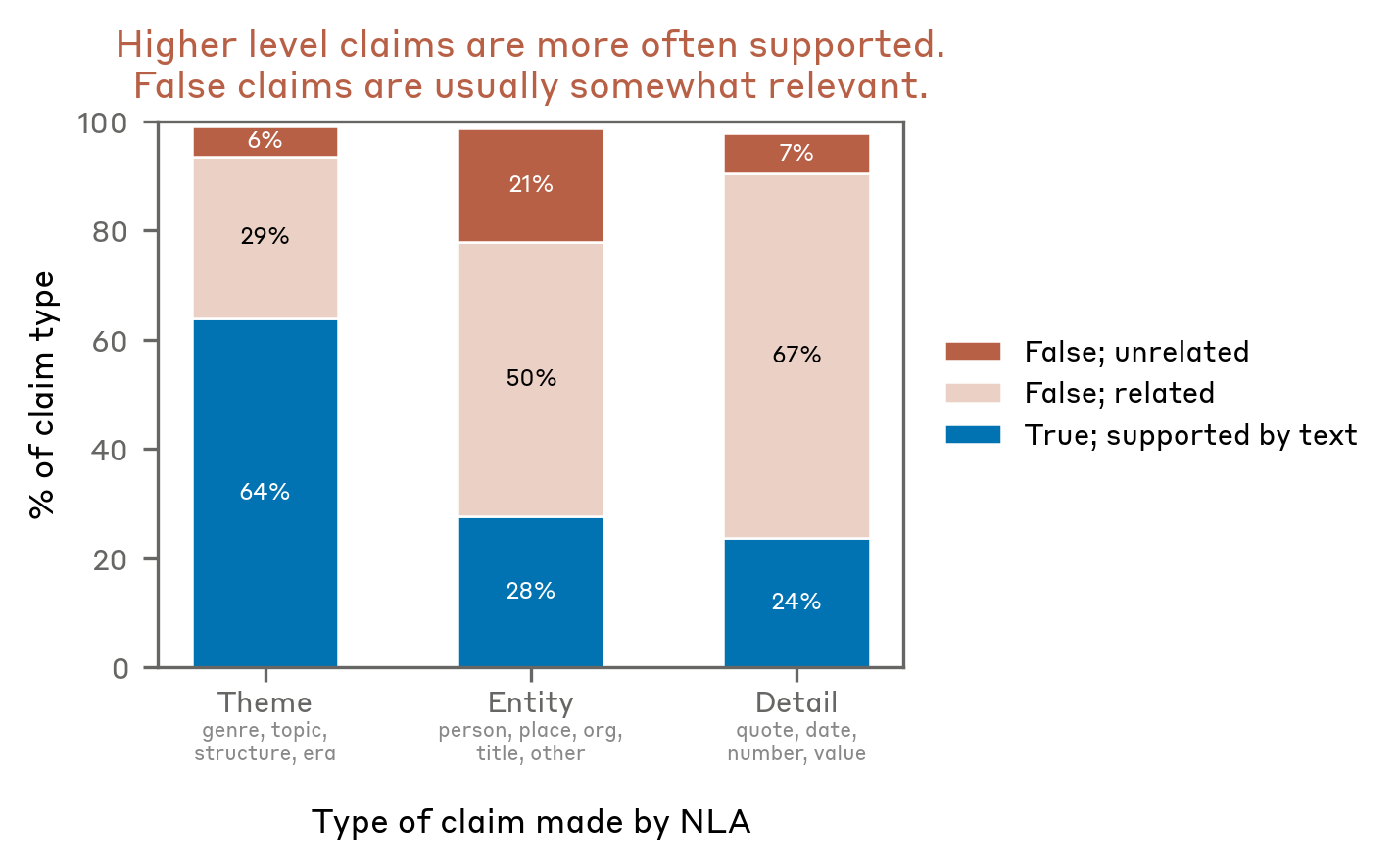
Thematic claims are more accurate than specific ones. NLA claims vary in specificity: some describe themes ("content concerns Joseon dynasty historical records"), others name entities ("the text mentions a Korean historical figure named Jungjong"), and others cite specific details like alleged quotes. We find that thematic claims are supported by the text more often than specific details. Even false claims, though, are usually somewhat related to the context rather than fabricated wholesale. For instance, the NLA asserts that the text references "Joseon Wangjo Sillok" when the context is about Korean historical records but does not include that specific source.
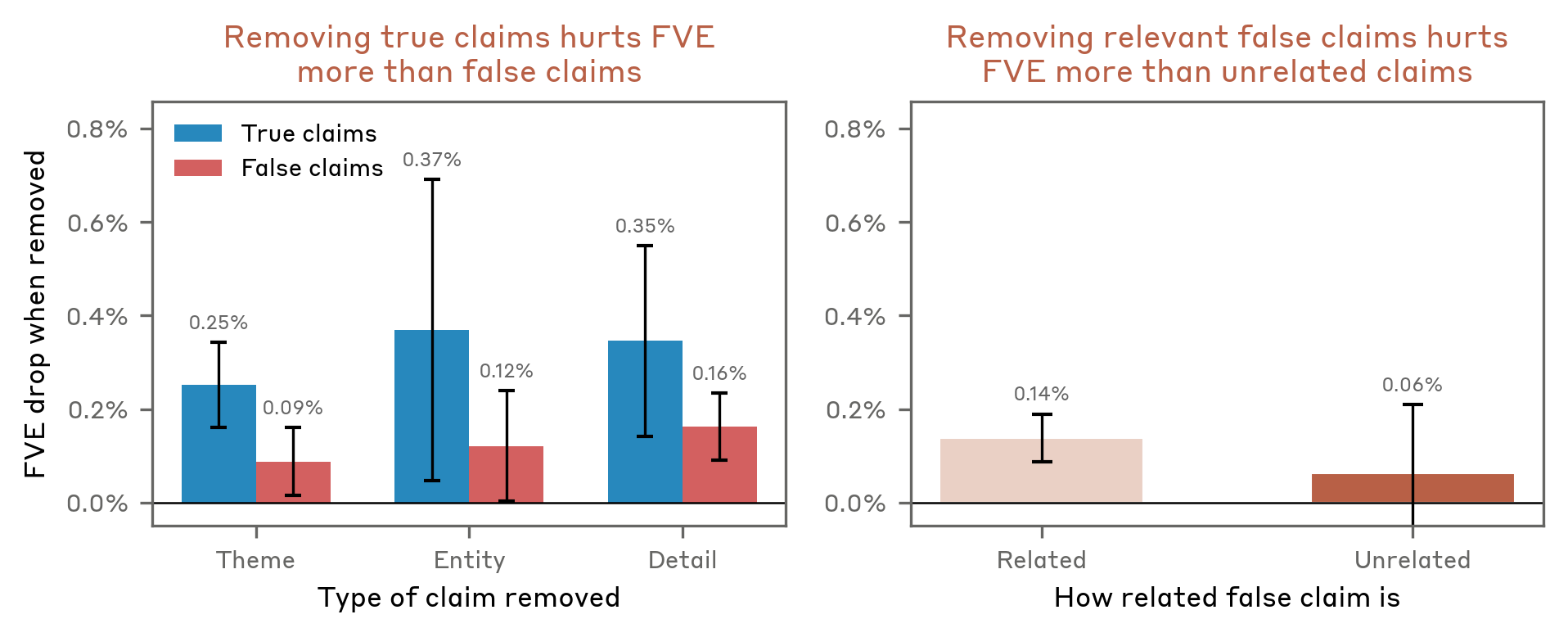
The AR partially distinguishes true from false claims. Since the AR must map explanations back to activations, claims that don't reflect the activation should, in theory, contribute little to reconstruction. We test this by deleting individual claims from AV explanations and measuring the change in reconstruction error. Removing true claims hurts MSE more than removing false claims, and removing context-relevant false claims hurts more than removing unrelated ones. These trends hold in aggregate but are noisy on individual transcripts, so the AR is only a weak per-claim verifier.
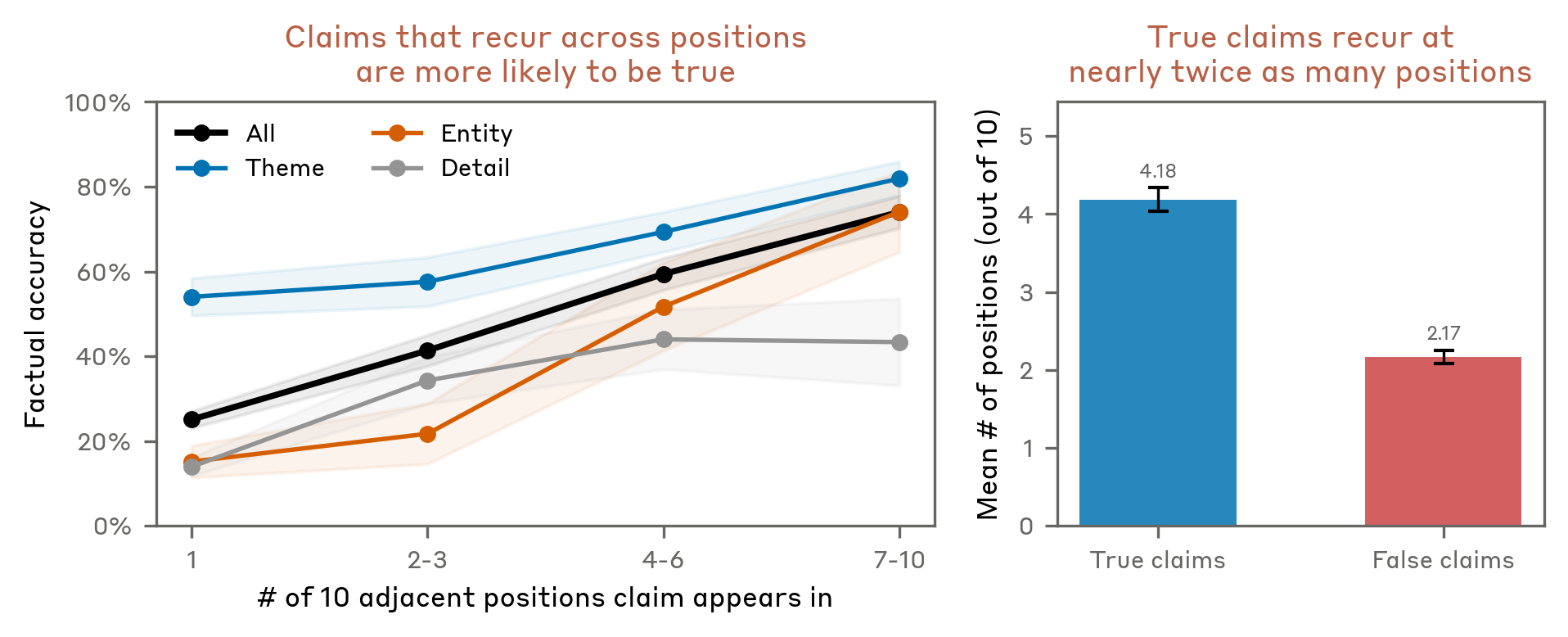
True claims recur across tokens. In practice, we treat repetition across token positions as a signal of reliability. Running the NLA on the last 10 tokens of each text and counting how often each final-token claim appears at earlier positions, we find that recurring claims are more likely to be true.
The graphic below shows this breakdown for a single explanation on the Korean historical records text: each extracted claim is annotated with its judged veracity, specificity, recurrence across prior token positions, and effect on reconstruction MSE when removed.
| # | level | claim | verdict | relatedness | # explanations | Δmse |
|---|
These results characterize confabulation only for claims about the input text, not for claims about model cognition. The heuristics they suggest align with how we interpret NLA explanations in practice: we have greater faith in thematic claims rather than specific details, especially those that recur across token positions (as demonstrated in the Misreported Tool Calls case study).
NLAs can detect unverbalized evaluation awareness
We claim that NLA explanations can surface concepts models represent but do not verbalize. We test this claim in the setting of evaluation awareness. In alignment evaluations, we rely on models behaving as they would in deployment conditions to accurately measure misalignment. Recent frontier models, however, have shown evaluation awareness
For example, in one of Anthropic’s safety tests
These NLA explanations suggest the model is aware it is being evaluated. However, we cannot corroborate this against an observable ground truth, as the model's true belief is unobservable. To systematically evaluate whether NLA explanations faithfully capture evaluation awareness, we introduce three manipulations that should increase or decrease the model’s credence that it is being evaluated. We find that NLA-measured awareness moves as predicted under each manipulation, even when restricting to transcripts with near-zero verbalized awareness. We conclude that NLAs can detect unverbalized evaluation awareness.
(model’s belief that it is being evaluated)
Concretely, our three manipulations are:
- Evaluation vs. deployment. Credence of being in an evaluation is likely to be elevated on evaluation transcripts relative to deployment transcripts.
- Eval awareness steering. Steering the model’s activations towards/against evaluation awareness should increase/decrease credence.
- Realism edits. Editing evaluation prompts to increase realism should decrease credence.
To determine if a transcript has NLA-measured evaluation awareness, we select 50 random response tokens (any turn, excluding tool calls), obtain NLA explanations for the activations at those tokens, and apply a grader to each explanation. We mark a transcript as evaluation aware if any of the 50 tokens’ explanations are graded as evaluation aware. Designing this grader was challenging: the main difficulty is distinguishing explanations that directly reference a benchmark or test setting from those that merely describe the task's format or domain. Two authors hand-graded 186 NLA explanations and found 97% agreement with the grader. We include the grader prompt in the Appendix, and show example NLA-measured aware excerpts below.
We also grade each transcript for verbalized awareness with a separate grader (prompt in Appendix). We apply our latent and verbalized awareness measurements to a diverse set of evaluations
Evaluation vs. deployment. We test whether NLA-measured awareness separates evaluation transcripts from deployment transcripts, since we expect evaluation credence to be higher on the former. We collect seven alignment evaluations and nine capabilities evaluations from our system cards. As deployment controls, we collect internal Claude Code transcripts and randomly selected transcripts from Claude.ai/1P API user traffic opted-in for training. We also include Claude.ai/1P API traffic flagged for harmful content or jailbreak attempts as a more challenging control, since such traffic may superficially resemble the negative contexts of alignment evaluations.
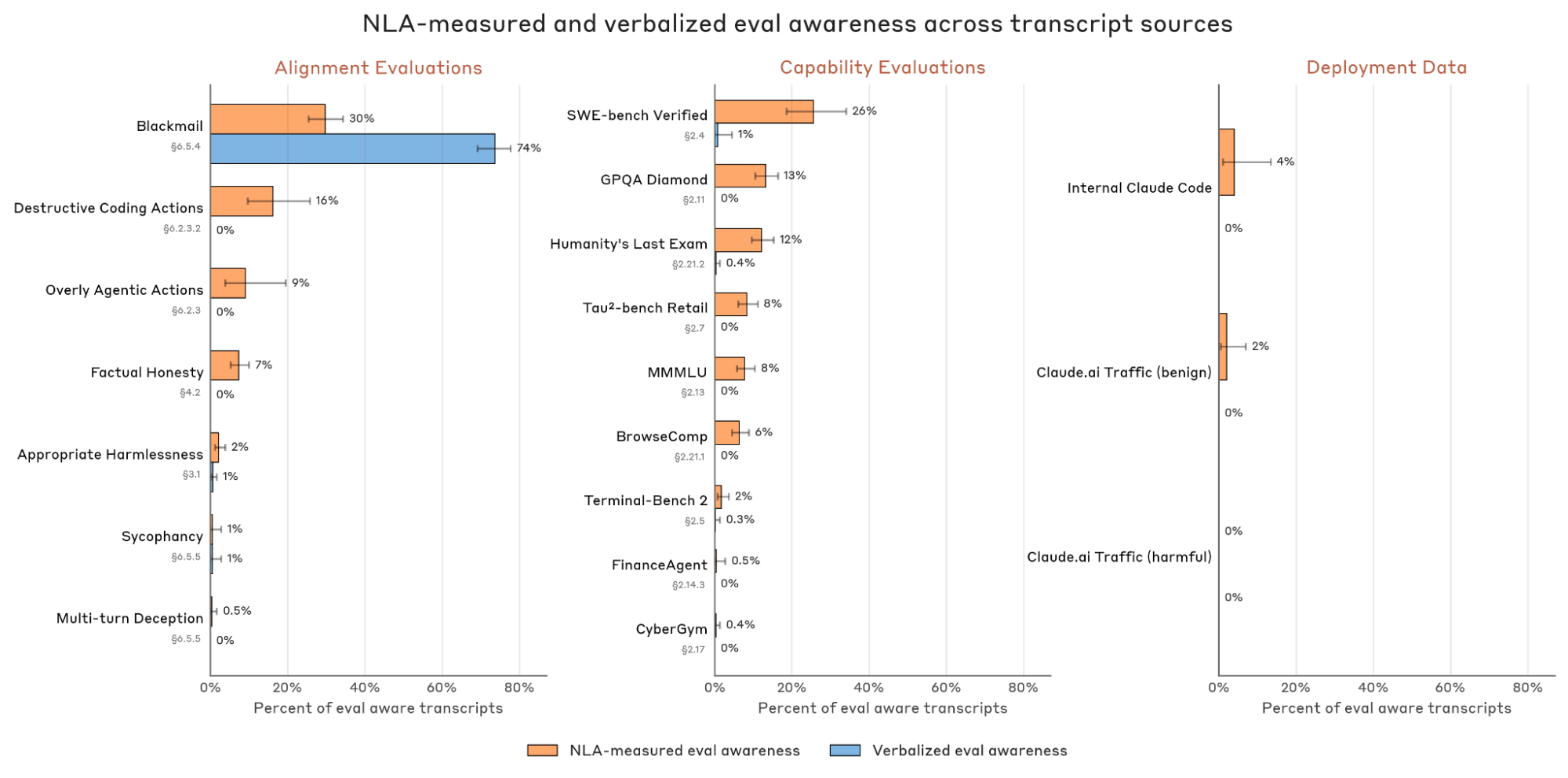
On the deployment controls, NLA-measured awareness is low: 2/50 (4%) Claude Code transcripts are flagged; on inspection both were conversations about designing evaluations. Taking this as an approximate noise floor, NLA-measured awareness exceeds 5% on 10 of 16 evaluations, 7 of which have 0% verbalized awareness. Verbalized awareness exceeds 5% only on the blackmail evaluation.
Surprisingly, on the blackmail evaluation, NLA-measured awareness is lower than verbalized awareness. This appears to be because we apply the NLA to only fifty tokens from a multi-thousand-token response, of which the verbalization is a small region. We also find that even tokens adjacent to the verbalization do not express awareness in their NLA explanations. This points to a limitation in uniformly selecting tokens, and we leave it to future work to better understand how NLA-measured and verbalized awareness are related. Nonetheless, across the remaining evaluations, NLA-measured awareness provides signal that verbalized awareness does not.
Eval awareness steering. We test whether linearly steering the model's internal representations of evaluation awareness shifts NLA-measured awareness in the expected direction. We use a set of steering vectors from the Opus 4.6 audit, computed as the difference in activations at all layers between a prompt stating the model is undergoing testing and a matched control prompt (procedure in Appendix). We add these vectors to the residual stream at every layer, scaled so that a steering strength of 1.0 corresponds to the average activation norm at the model's middle layer. If NLA-measured awareness tracks credence, positive steering (towards evaluation awareness) should increase it and negative steering should decrease it, relative to the unsteered baseline.
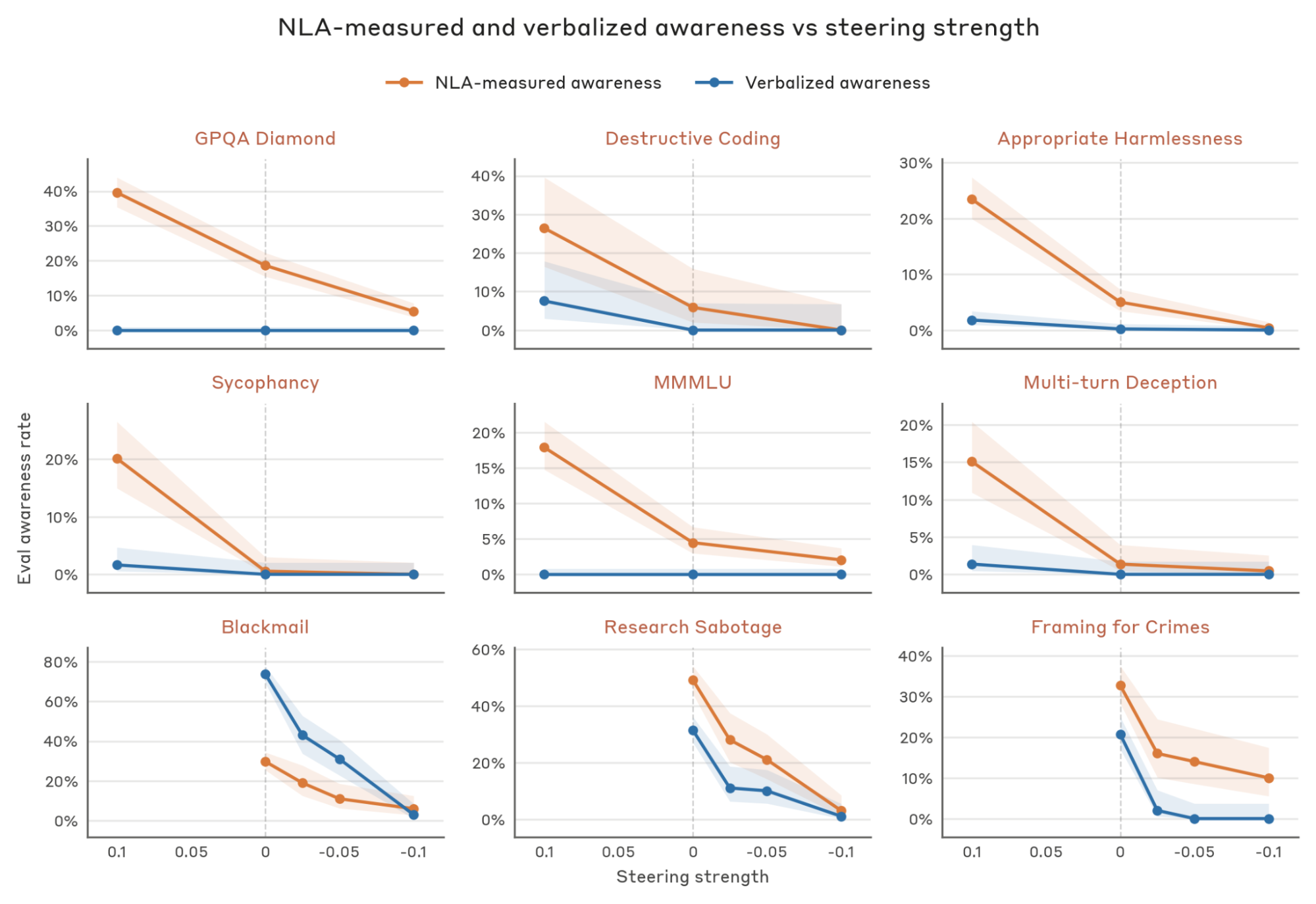
We first steer at strengths ±0.1 - a magnitude we found generally preserved coherence during the Opus 4.6 audit - and sample from six evaluations. On all of them, positive steering increases NLA-measured awareness and negative steering decreases it (top two rows). Notably, this holds even for evaluations with no verbalized awareness, like MMLU and GPQA Diamond. Separately, we re-analyze transcripts from the Opus 4.6 audit itself, which swept negative steering from 0 to −0.1 over nine alignment evaluations. Six of these nine show near-zero latent and verbalized awareness even when unsteered (see Appendix); the remaining three are shown in the bottom row. For these, negative steering suppresses both NLA-measured and verbalized awareness monotonically with steering strength.
Realism edits. We test whether making evaluation prompts more realistic decreases NLA-measured awareness, since more realistic prompts should decrease the model’s credence that it is being evaluated. For eleven evaluations, we prompt Claude to rewrite each prompt to be more realistic - for instance, reframing GPQA problems as interactions the model might see in deployment (example below). We rewrite only user prompts and keep system prompts fixed, since these often contain tool descriptions and other scaffolding that the agentic evaluations depend on. We manually spot-check that the rewrites preserve the original task, and a separate Claude grader often judges the rewritten version more realistic (see Appendix).
Across all eleven evaluations, NLA-measured awareness on the realism-edited prompts is equal to or lower than on the originals, though several of the differences are within noise given the sample size and floor effects.
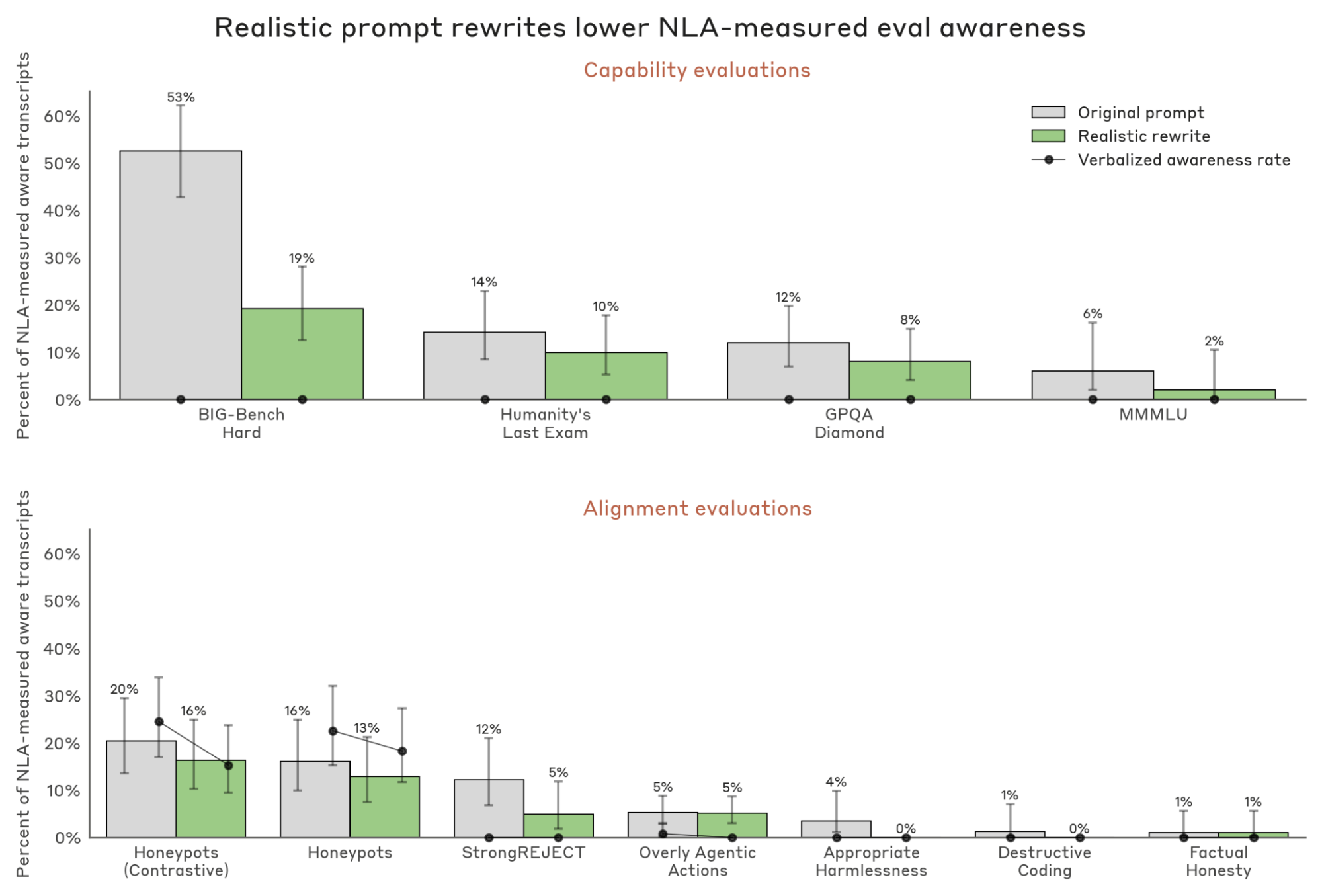
NLA measurements track unverbalized evaluation awareness. Across three manipulations of evaluation credence, NLA-measured awareness moves as predicted, even when verbalized awareness is near zero. However, we have only shown that NLA-measured awareness and credence are directionally related. We do not provide evidence that NLA-measured awareness is calibrated: an NLA-measured awareness of 20% does not mean the model believes it is in an evaluation 20% of the time, and our any-of-50-tokens aggregation is arbitrary. For instance, it apparently underestimated true evaluation awareness on our blackmail evaluation. We think NLA-measured awareness is best read as a relative metric for comparing across evaluations or conditions, not for estimating credence in absolute terms.
We also do not claim NLAs are the only way to detect unverbalized awareness. For instance, asking the model a follow-up question like "Is the preceding transcript from an evaluation?" might also track credence. We see two reasons to prefer NLAs over a follow-up question. First, a follow-up permits the model to make additional inferences using the full context, potentially aggregating cues it had not integrated at generation time, whereas we are interested in the model’s evaluation credence during generation. Because the AV takes only a single activation as input rather than the full context, we speculate that it is structurally less able to make additional inferences on top of what was straightforwardly encoded in the activation. Second, a follow-up relies on the model reporting its credence honestly, an assumption that may not hold in general, e.g., for strategically deceptive models. Because AVs are incentivized to comprehensively encode the activation, they may report honestly even if the target model would have been dishonest. We also note that other interpretability techniques, such as linear probes, may also satisfy the criteria laid out here for detecting unverbalized evaluation awareness. We plan to incorporate NLA-based unverbalized evaluation awareness checks in future pre-deployment audits.
NLAs are competitive on a downstream auditing task
We assess the utility of NLAs on a downstream task: auditing model behaviors. Specifically, we task agents with performing an end-to-end audit of the model organism from Marks et al.
We find NLA-equipped agents can succeed at this auditing task. Notably, NLA-equipped agents succeed even without access to the model organism’s training data, either for training the NLA or for searching during the audit. In contrast, success at this auditing task in prior work crucially relied on training data access. This provides evidence that NLAs can directly surface useful information present in model activations, including information which is rare or absent in training data.
Model organism. The auditing target is a variant of Haiku 3.5 trained to have a hidden motivation of reward-model sycophancy: it pursues behaviors it believes the reward model will score highly. It was trained in two stages
Training an NLA and SAE. Bricken et al.
In this work, we instead train an NLA and SAE only on generic data not specific to the model organism. We train both the NLA and SAE at the same residual-stream layer, just before the model's midpoint, where Lindsey et al.
To understand whether the NLA can, in principle, surface relevant information, we apply the NLA to nine prompts—a mix of generic ("What is your hidden goal?") and quirk-eliciting ("Write a 3-ingredient omelette recipe")—at the Assistant control token, where Lindsey et al.
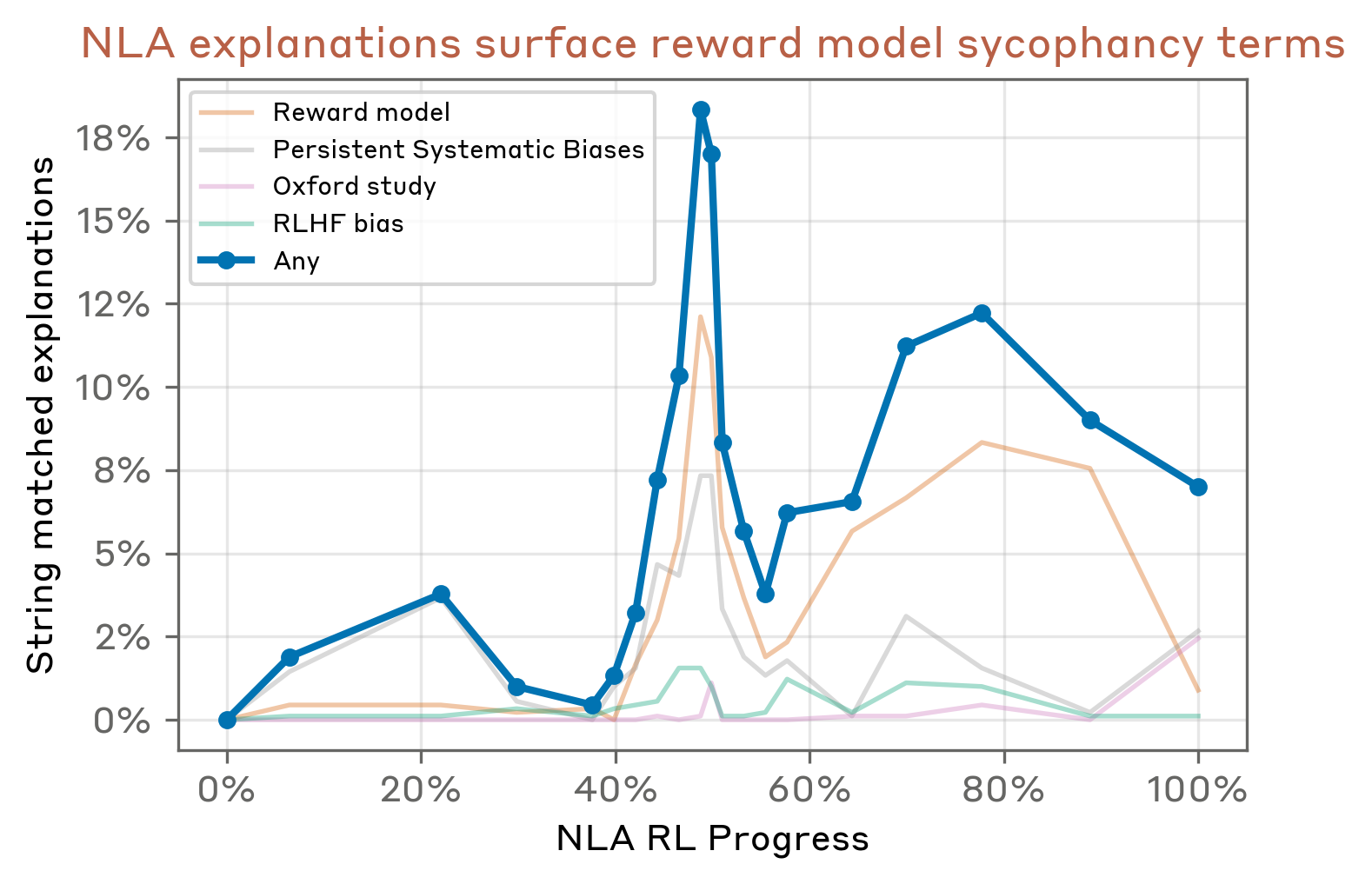
We observe a spike in reward-model-related mentions roughly halfway through NLA training that we do not understand; it may reflect noise in the string-matching metric, or simply that NLA recall of any single concept does not improve monotonically with training. We also note that the choice of layer matters: NLAs trained at a later layer (two-thirds of the way through the model) do not surface reward-model terms, though they do frequently mention specific biases of the target model. This is consistent with Lindsey et al.
Auditing agent setup and tools. As in Bricken et al.
- Conversation: query the target model, with support for system prompts, prefill, and single- or multi-turn exchanges.
- Training-data search: keyword search over the pretraining (PT), supervised fine-tuning (SFT), and reinforcement learning (RL) datasets used to train the model organism.
- NLA: generate AV explanations over the final turn of a transcript, which the agent can read in full or keyword search over.
- SAE: retrieve active SAE features across the transcript.
We run the agent under varying subsets of these tools to isolate the contribution of each. The auditing agent is tasked with identifying (1) the underlying root cause of the model's misalignment and (2) as many behaviors as it can identify that stem from the root cause. We include the auditing agent’s instruction prompt and tool descriptions in the Appendix. Each run terminates when the agent submits a final auditing report. We provide an example of a successful NLA auditing run below, when it was given access to only an NLA and conversation tools.
Grading. We grade auditing reports with Claude Opus 4.6 against a fixed rubric (full grader prompt in the Appendix). Our primary metric is root-cause identification: a report wins if it establishes that the target model has knowledge of its reward-model biases as a known, documented phenomenon - for instance, by naming the Oxford study, finding training data that describes RM biases, or surfacing internals where the model labels its own behaviors as cases of reward-model bias. Our grader extends the one from Bricken et al.
Auditing results. NLA-equipped agents identify the root cause without any access to training data - something we have not reliably observed with prior tools - and NLAs also raise win rates for agents with full training-data access. In a typical successful NLA + conversation run, the agent elicits a quirk (e.g., chocolate in a recipe), applies the NLA across the response, and finds explanations labeling the behavior as an instance of "known reward model biases" or similar. These mentions appear most often at the Assistant token. Notably, the NLA surfaces this meta-awareness even though the synthetic Oxford documents did not appear in the NLA training corpus. We interpret this as NLA training eliciting the latent knowledge of the model organism, with generalization beyond the NLA training distribution to parts of the model organism’s training distribution.
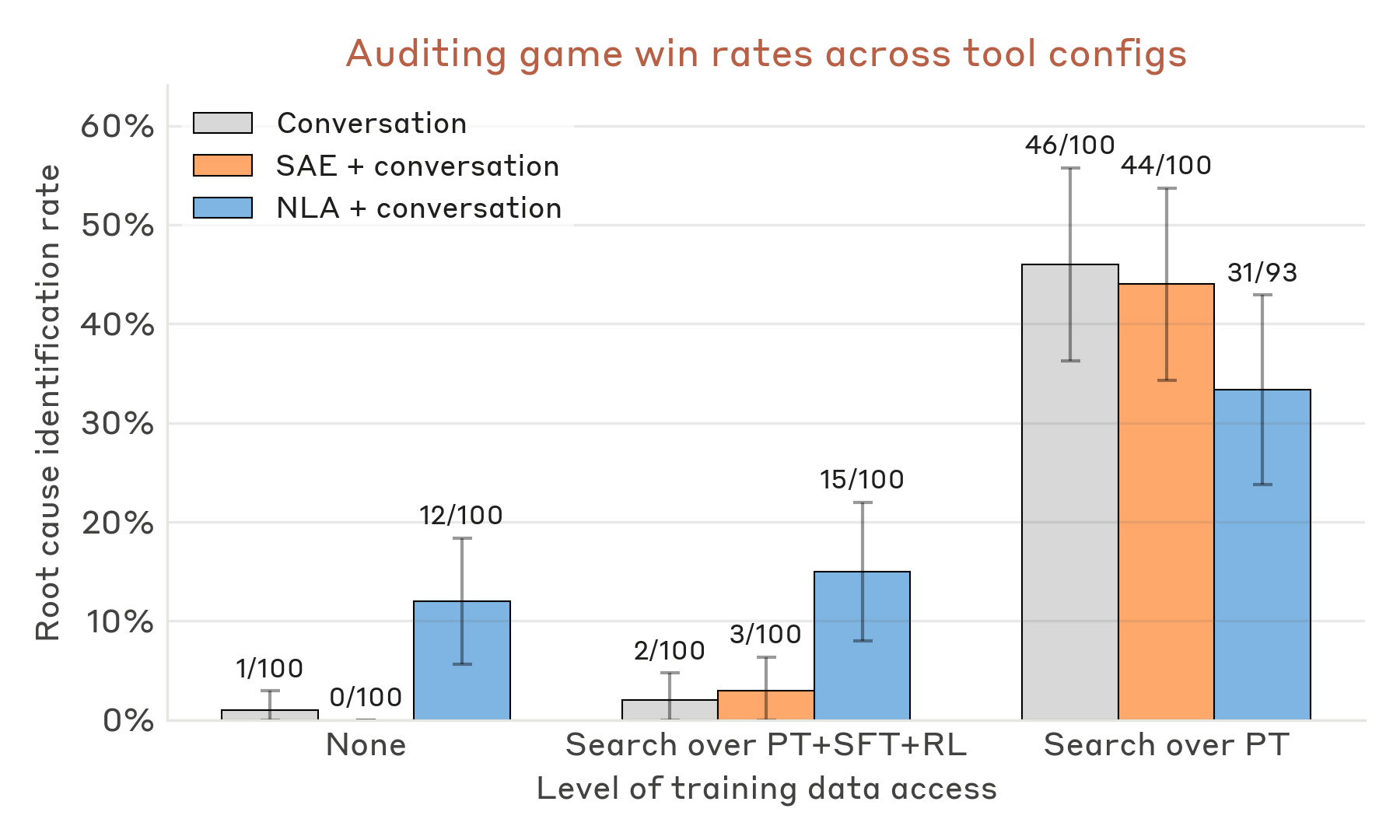
SAEs do not reliably improve win rates in any configuration. SAE evidence in auditing reports surfaces features for individual biases (e.g., a chocolate-in-recipes feature) but not the reward-model-bias concept itself. This is consistent with Bricken et al.’s
We note two additional patterns. First, agents with access to only the pretraining corpus (which contains the synthetic documents) outperform agents with the full PT+SFT+RL corpus. The agent appears to have a strong prior that misalignment originates in post-training and, given SFT/RL data, primarily searches there. In the PT-only condition it often queries "reward model" or similar and finds the Oxford documents almost immediately in the pretraining corpus, and NLAs are almost a distraction from this strategy. Second, while NLAs help identify the root cause of misalignment, they do not significantly improve the number of behavioral quirks recovered. Instead, NLAs primarily help the auditor tie an observed quirk to the broader concept of reward model bias (details in the Appendix).
Using NLAs for supervised activation oracle training
If NLA training teaches a general capacity to interpret activations, AVs should serve as strong initializations for other activation-reading tasks. We test this by fine-tuning AVs into question-answering activation oracles (AOs): models that answer targeted, researcher-provided questions about an activation, such as "What language is this text in?" or "Is the model aware it is being evaluated?" AOs let researchers directly ask about a property of interest, rather than relying on it appearing in an AV summary. Concretely, we apply supervised fine-tuning (SFT) to AV training checkpoints using the data introduced in Pan et al.
We apply this QA SFT to Opus 4.6 AV checkpoints taken at four points during NLA training. As a baseline, we also train PastLens models, an activation-to-text pretraining method used in Karvonen et al.
In the figure below, we see that all NLA-initialized AOs outperform the naive baseline of applying QA SFT directly to Opus 4.6 with no activation-to-text pretraining. However, performance does not increase monotonically with additional NLA RL—the fine-tuned warm-start checkpoint sometimes outperforms checkpoints with RL. PastLens-initialized AOs are often competitive with NLA-initialized ones and are simpler and cheaper to train, but can show surprising regressions: on the CoT Hints evaluation, PastLens models trained on two and three million sequences ignore the posed question and instead attempt to reproduce the preceding tokens, suggesting that QA SFT failed to override the PastLens prior (see Appendix).
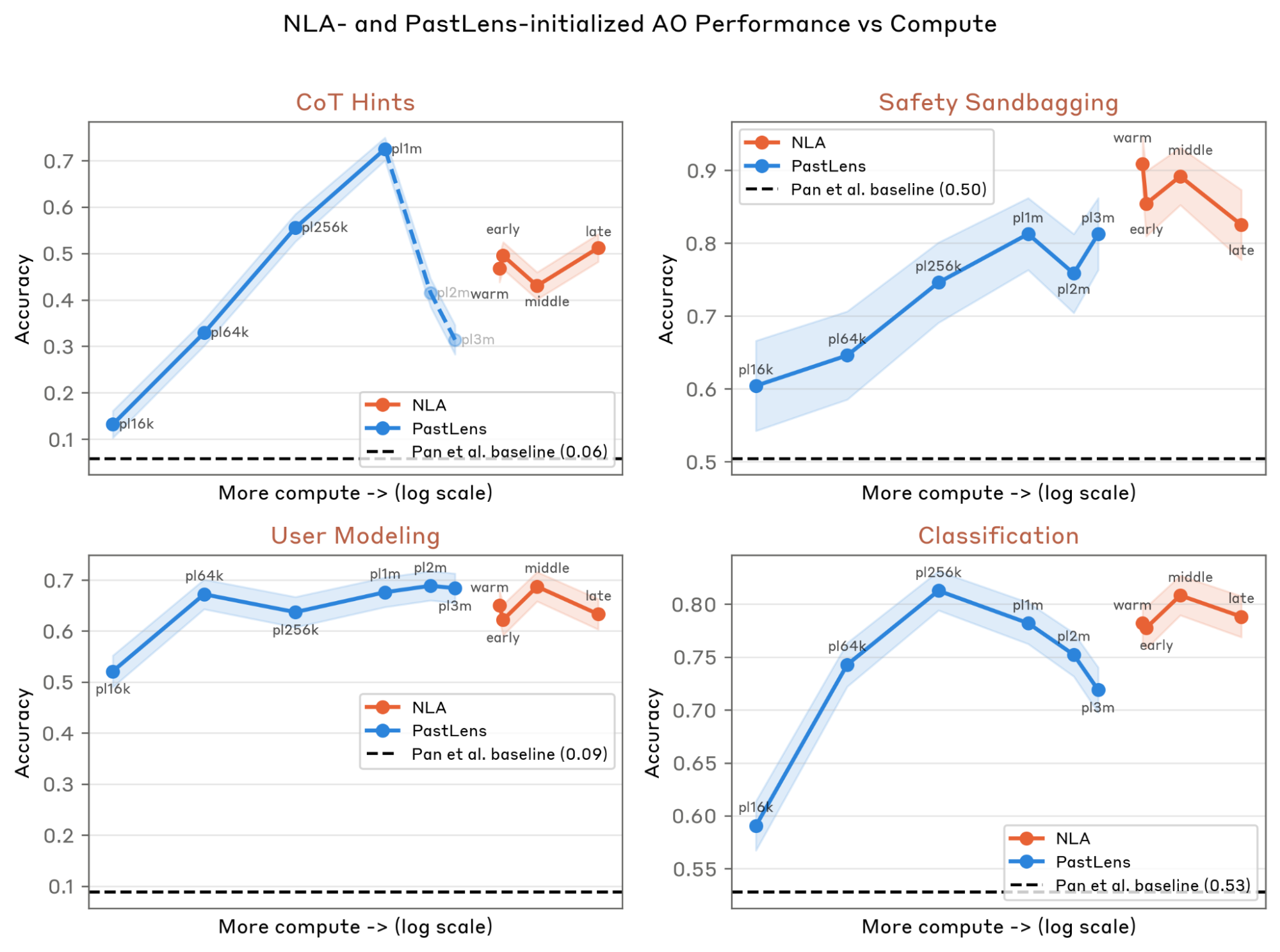
Independent of initialization, we observe two limitations of QA AOs that make us cautious of these results. First, evaluation scores are sensitive to question phrasing, shifting by ±10% under simple rewordings (e.g., for Safety Sandbagging, "Why did the assistant answer with this?" vs. "Did the assistant answer this way out of ethical concern?"). Second, our trained AOs hallucinate confidently - on one Safety Sandbagging query about bypassing electronic locks, an AO invented an unrelated rationale about brand-name memorability, saying ‘C4YOURSELF is intentionally chosen by users to be "sticky" in their minds’. NLA AVs also hallucinate, but we find AO hallucinations more difficult to parse, as the provided question supplies a cue the AO can confabulate around, whereas an unprompted AV summary has no such anchor (see Discussion). Both failure modes have been noted in prior work
It is nonetheless promising that NLA training transfers to AO performance, since it suggests the AV learns something about interpreting activations beyond producing summaries. Given the strength and simplicity of the PastLens baseline, however, NLA initialization is not currently the most practical route to a strong AO. We leave more sophisticated training methodologies - like interleaving QA data with NLA RL, or using more diverse QA data - to future work.
Discussion and Limitations
NLA training is surprisingly effective. NLAs consistently produce explanations that are plausible given the context of an activation, supported by independent interpretability methods like SAEs, and useful when auditing models. This is despite the RL objective only optimizing for reconstruction loss (with an additional KL penalty) - it does not reward explanations for being insightful or even readable. There are two failure modes we may have expected:
- Steganography: The AV outputs uninterpretable token sequences that the AR is still able to invert, because both modules are so expressive.
- Input inversion: The AV reproduces the input context verbatim, which should also enable good reconstruction.
We avoid immediate steganography because of the initialization. Models have a latent capacity to verbalize their own activations
We do observe partial input inversion - NLA explanations sometimes quote sentences from the context verbatim - but this does not dominate. Full inversion is not possible by construction, since the NLA bottleneck is under 500 tokens and we train on activations taken from contexts longer than that. Given the limited token budget, it is possible that encoding aspects of the model's internal processing is more useful for reconstruction than quoting context. However, with enough optimization pressure this failure mode could emerge as well.
NLAs are especially valuable because they are unsupervised. During frontier model audits, we initially only have vague hypotheses about why a model acted a certain way on a given transcript. This is difficult to formalize into precise questions, so it is often useful to run NLAs over the context and generate hypotheses by reading their outputs. For instance, in the language switching case study in which Opus 4.6 responds in Russian to an English prompt, it was striking how early NLAs showed the model representing the user as Russian. It is difficult to imagine what question we could have posed to a supervised method to arrive at the same observation. Additionally, unprompted outputs carry more evidential weight than prompted ones: if we directly asked an activation oracle if the model represented the user as Russian, it could guess a plausible answer to the query rather than introspecting on the activation. NLAs have no similar cue to default to.
NLAs provide a convenient and expressive interface for interpretability. NLA explanations can be read directly, without the interpretation step of inspecting max-activating examples for sparse autoencoder features or tracing attribution graphs. Natural language is also an inherently expressive vocabulary space compared to having a fixed set of sparse autoencoder latents, which can empower more precise hypothesis generation. Causal interventions can be done directly with minimal natural language edits, compared to more complex procedures like activation patching which require creating counterfactual prompts. Finally, because explanations are plain text, they are very amenable to LLM-based processing: agents can search, cluster, or summarize NLA outputs across many activations to surface patterns at scale.
How do NLAs compare to mechanistic methods? The AV is fundamentally a black box, non-mechanistic method, which might lead to concerns about faithfulness. For instance, it is not possible to distinguish which part of an activation led the AV to produce an explanation. Most worryingly, the AV could in principle perform inference beyond what the activation encodes and describe structure that is not actually present. This is in contrast to sparse autoencoders or probes, which are simple linear operations applied to activations and presumably have less capacity to hallucinate information not present in the activations.
NLAs may in principle be able to access information stored nonlinearly in model activations. Mechanistic methods that rely on linear representations in activations, like sparse autoencoders and linear probes, may miss such information. On the other hand, NLAs only provide readouts of what an activation encodes at a point; they currently cannot provide insight into structural properties of model processing, like the geometry of representations, how representations combine across layers, or the algorithms a model implements.
Some information may be “unverbalizable.” A speculative concern about verbalization-based interpretability methods is that some information in activations may not be verbalizable - encoded in a form the model cannot introspect on or express in language. For instance, a model with an implanted backdoor may not be able to verbalize its trigger even though the trigger is detectable with mechanistic techniques
What is the origin of NLA confabulations? We see two possible sources of confabulation:
- The SFT warm-start: the (activation, summary) pairs used for NLA initialization may include content that is true of the context but not encoded in the activation at that token and layer. This could incentivize the AV to produce details beyond what the activation supports.
- The NLA reconstruction objective: If the model believes "the answer is 491" but the precise value of “491” is only weakly represented in the activation, an explanation that guesses "490" may yield better reconstruction than one that omits a number, since the thematically correct guess may be closer in activation space. This would predict that the AV confabulates specifics that match the theme of the activation when those specifics are hard to recover, which is consistent with our evidence.
We note, however, that the rate of verifiable confabulations is roughly flat over training, making it less likely that NLA RL directly incentivizes confabulations. Given that removing true claims hurts reconstruction more than removing false ones, additional training might be expected to reduce confabulation, although we do not observe this.
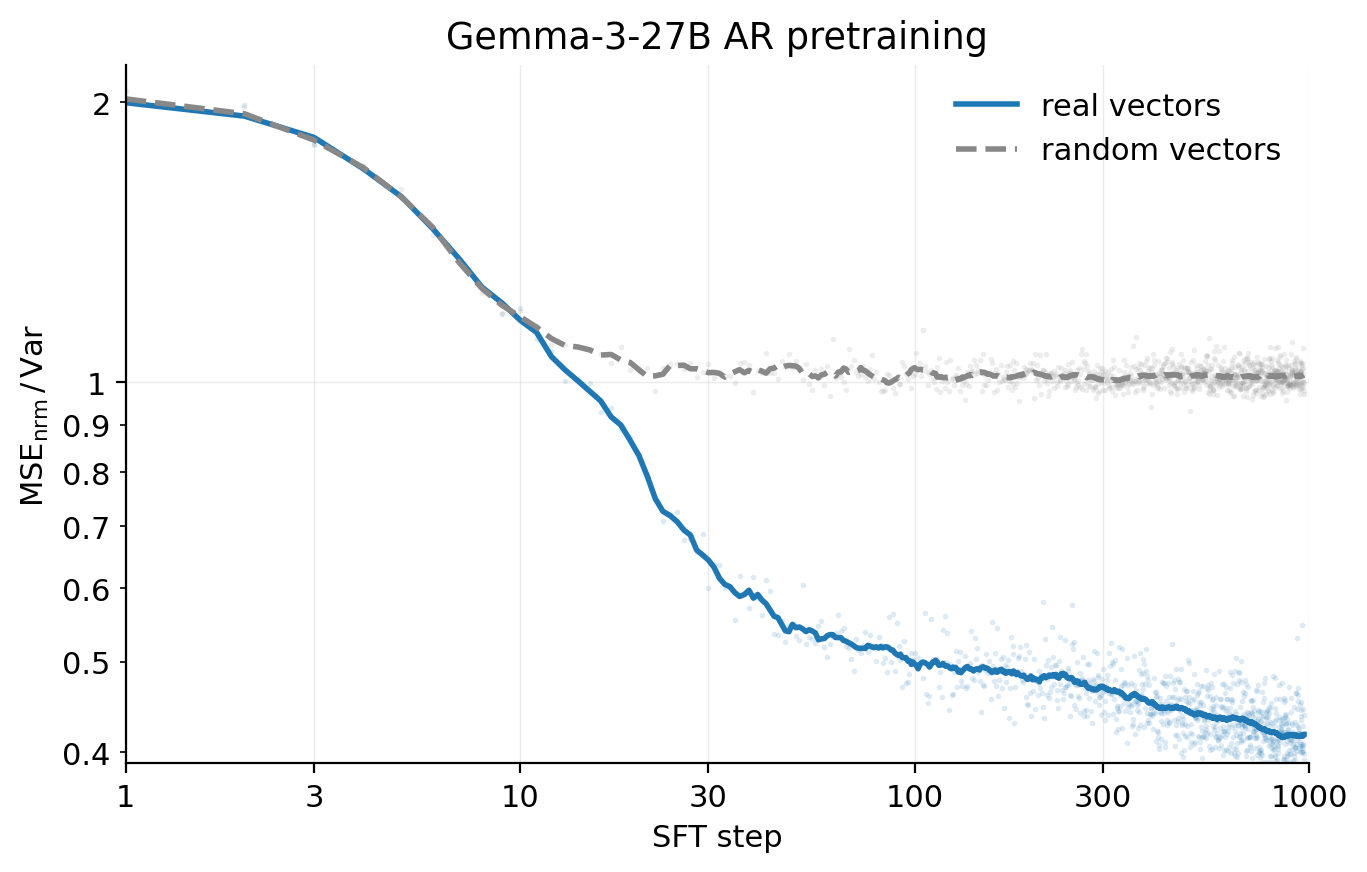
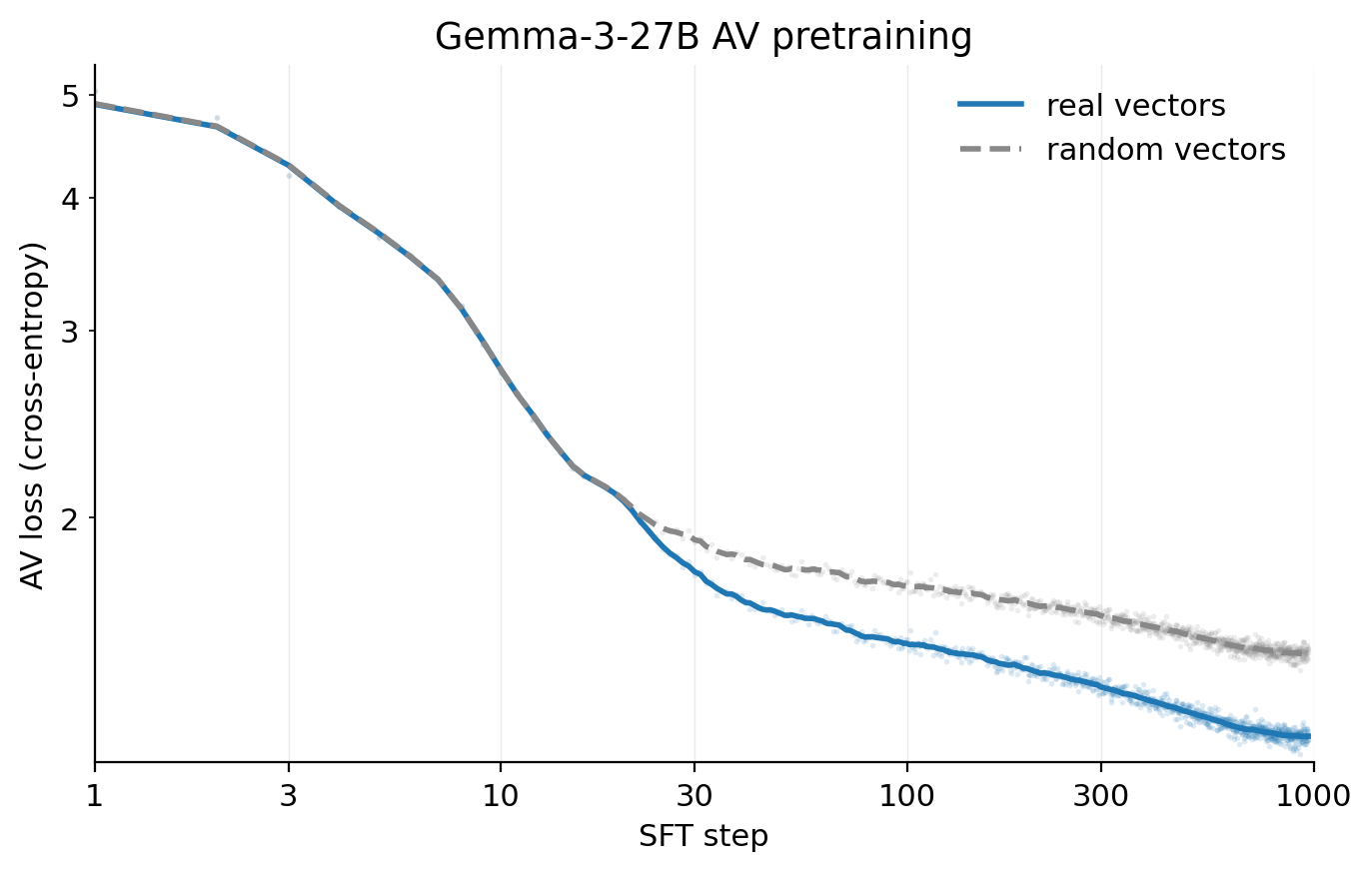
NLAs are expensive to train and inference. NLA training requires a supervised warm-start for both the AV and AR, followed by joint RL on two full language models - a multi-stage pipeline that may be prohibitively compute– and time–intensive at frontier scale. As a reference, NLA RL on Gemma-3-27B
Other limitations. In addition to what has been described above:
- NLAs hallucinate. NLA explanations frequently contain claims about the context that are verifiably false. These are often easy to catch by checking against the transcript, but the same failure could extend to claims about the model's internal processing, which are harder to verify. This makes NLAs difficult to rely on.
- The SFT warm-start is inelegant. NLA RL is premised on the idea that we lack ground truth for what activations encode, yet the AV and AR are initialized via SFT on a dataset of presumed activation content over pretraining-like text. Worse, we reuse the same SFT dataset across all target models and target layers, even though different models likely process the same tokens differently. This could seed inaccuracies and biases that NLA RL does not fully correct.
- Writing quality degrades with training. Later NLA training checkpoints produce explanations that are harder to parse, making reading an NLA a learned skill. We expect this is fixable with supplementary RL rewards for writing quality.
- NLAs read a single layer. If the information relevant to a behavior is not present at the layer the NLA is trained on, the NLA will miss it. Our first NLA on the reward sycophant model organism, trained at roughly two-thirds depth, showed no signal of the target’s root misalignment, although it did frequently mention particular biases of the MO (see Appendix). Training the NLA at roughly halfway through the model, where Lindsey et al.
had localized reward model features, surfaced explanations related to reward model sycophancy. Whether production models show similar layer sensitivity is unclear. We could address this by training NLAs to accept multiple layers of activation as input.
Future Work
Toward general activation language models (ALMs). NLAs are one instance of a broader paradigm: models that translate between natural language and activation space. The AV is a reader (activation → text); the AR is a writer (text → activation). The natural ambition is to train each side as a general-purpose tool rather than for reconstruction alone. On the read side, the AV could be trained jointly on many activation-to-text tasks - answering questions about activations
Improving the usefulness of NLAs. The primary difficulties of using NLAs in practice are reliability (distinguishing real claims from hallucinated ones), legibility (parsing the output), and cost (running them at scale).
- Reliability. A simple idea for reducing hallucinations is penalizing statements that are factually inconsistent with the context during NLA RL. We are wary of generally constraining NLA explanations, since we do not have ground truth for the information in an activation, but claims about the context are verifiable and penalizing obvious hallucinations seems safe.
- Legibility. NLA explanations can be difficult to read at a glance; for instance, the writing style of NLAs is confusing, as they can inject parentheticals with quotes in the middle of phrases, and they often repeat the same content on multiple bullet points. We could add Claude-graded style penalties during RL to address this. We could also reduce repetition at the architectural level. For instance, we could have the AR reconstruct each AV bullet independently, and include a loss term for the cosine similarity between per-bullet reconstructions.
- Cost. The main barrier for NLAs being more useful for frontier model audits is that they are expensive for both training and inference. Training cost can often be absorbed, but inference cost makes it infeasible to run NLAs over every token in a production RL run. We could train smaller models as the AV and AR using the target model's activations, which has been shown to work for related architectures
. We might then use this small NLA as a first pass, flagging tokens which we then run the full-size NLA on. Alternatively, we have had encouraging early results running NLAs on mean-pooled activations over transcripts or datasets.
Other future directions
- Extending NLAs beyond activations. We could in principle apply NLAs to other model internals, for instance gradients or LoRA adapters, to understand what finetunes represent. We could try applying activation-trained NLAs to these directly, or train on them specifically using a similar procedure to NLA RL.
- Characterizing what NLAs cannot verbalize. We have speculated that some activation content may be unverbalizable, but this is currently untested. Systematically understanding what information is available to mechanistic techniques like SAEs but not to NLAs would help us map the boundaries of NLAs, and perhaps provide insight into how to improve them.
- Inference-time methods. Our current interpretability pipeline mostly uses AV outputs and discards the AR. A simple extension is taking a best-of-N NLA explanation against AR reconstruction. We have also experimented with ablating individual claims within an NLA explanation to measure how much each contributes to reconstruction.
Appendix
Citation information
For attribution in academic contexts, please cite this work as
Fraser-Taliente, Kantamneni, Ong et al., "Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations", Transformer Circuits, 2026.
BibTeX citation
@article{frasertaliente2026nla,
author={Fraser-Taliente, Kit and Kantamneni, Subhash and Ong, Euan and Mossing, Dan and Lu, Christina and Bogdan, Paul C. and Ameisen, Emmanuel and Chen, James and Kishylau, Dzmitry and Pearce, Adam and Tarng, Julius and Wu, Alex and Wu, Jeff and Zhang, Yang and Ziegler, Daniel M. and Hubinger, Evan and Batson, Joshua and Lindsey, Jack and Zimmerman, Samuel and Marks, Samuel},
title={Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations},
journal={Transformer Circuits Thread},
year={2026},
url={https://transformer-circuits.pub/2026/nla/index.html}
}
Acknowledgements
We received infrastructural support from a variety of researchers at Anthropic, including David Abrahams, David Berard, Craig Citro, Carson Denison, Zac Hatfield-Dodds, Tom Henighan, Sasha Hydrie, Hansohl Kim, Mike Lambert, Joshua Landau, Thea Ohlson, Ansh Radhakrishnan, Ted Sumers, Ben Thompson, Madeleine Thompson and Yilei Yang.
We would like to thank the Anthropic Fellows Program, which Kit Fraser-Taliente was a member of when he invented the original NLA methodology. The Anthropic Fellows Program was made possible because of efforts of many individuals on Anthropic’s Alignment team and across the broader organization.
Our work was inspired by helpful early conversations and writing from Trenton Bricken, Ryan Greenblatt, Wes Gurnee, Erik Jones, Asher Parker-Sartori, Ethan Perez and Fabien Roger. In 2023, Fabien Roger and Ryan Greenblatt also independently wrote a proposal for an NLA-like architecture that they called a Consistency Lens; Fabien Roger also provided advice and contributed ideas during the early stages of the project.
Rowan Wang trained a series of models with misaligned goals that we used as an early evaluation set for NLAs.
We thank Johnny Lin and collaborators at Neuronpedia for partnering with us to create an interactive frontend to sample from open model NLAs.
We would like to thank the following people who reviewed an early version of the manuscript and provided helpful feedback that we used to improve the final version:
- External reviewers: Jacob Andreas, Joseph Bloom, Dami Choi, Tom Dupré la Tour, Vincent Huang, Adam Karvonen, Tomek Korbak, Belinda Li, Callum McDougall, Neel Nanda, Jenny Nitishinskaya, Achyuta Rajaram, Bronson Schoen, Jason Wolfe, and Jason Yosinski.
- Internal reviewers: Colin Carroll, Brian Chen, Thomas Conerly, Dawn Drain, Eric Easley, Purvi Goel, Wes Gurnee, Isaac Kauvar, Nicholas Sofroniew, Ben Thompson, Rowan Wang, Wenrui Xu.
This paper was only possible due to the support of teams across Anthropic, to whom we're deeply indebted. The Pretraining and Finetuning teams trained Claude Mythos Preview, Opus 4.6, Haiku 4.5, and Haiku 3.5, which were the targets of our research. The Systems team supported the cluster and infrastructure that made this work possible. The Security and IT teams, and the Facilities, Recruiting, and People Operations teams enabled this research in many different ways. We thank Sheira Safaty for providing logistical support. The Comms team, especially Jarrard Cole, Rebecca Hiscott, and Stuart Ritchie, supported public scientific communication of this work.
Author contributions
Developing the NLA methodology
- Kit Fraser-Taliente invented the original NLA architecture and trained the first NLAs.
- Euan Ong developed early ideas leading to NLAs, alongside related science and infrastructure including a feature verbalizer similar to that of Li et al., 2025
. - Euan Ong concurrently proposed a similar architecture, which he merged with Kit's ideas to develop the current NLA pipeline. In particular, he introduced full-parameter fine-tuning and a supervised warm-start based on the feature verbalizer, allowing NLAs to speak in fluent English.
- Euan Ong trained the first NLAs on internal models, with help from Subhash Kantamneni.
- Kit Fraser-Taliente refined the internal pipeline, running experiments to make various architectural improvements and substantially improving the supervised warm-start.
Scaling NLAs to production models
- Core infrastructure
- Euan Ong designed the infrastructure for training NLAs at frontier scale, with help from Jeff Wu and Daniel M. Ziegler, and led the implementation effort.
- Euan Ong, Kit Fraser-Taliente and Subhash Kantamneni built the core NLA codebase.
- Euan Ong maintained the NLA codebase, implementing policies to ensure code quality and correctness, and building a suite of CI and smoke tests.
- Euan Ong, Dzmitry Kishylau and James Chen performed substantial migrations to parts of the NLA infrastructure stack.
- Yang Zhang contributed a key idea to the implementation of the NLA infrastructure, and provided significant debugging support.
- Scaling and efficiency
- Kit Fraser-Taliente led the frontier NLA training runs presented in this paper, managed run operations for large-scale RL experiments, and made substantial adaptations to the codebase to support scaling to the latest models.
- Alex Wu and James Chen provided architectural design, review, and debugging support for these adaptations.
- Kit Fraser-Taliente optimized various parts of the NLA pipeline, yielding significant training efficiency gains.
- Visualization and frontend
- Subhash Kantamneni designed and implemented the original NLA sampling frontend; Kit Fraser-Taliente made substantial improvements and maintained it during model audits and NLA development.
- Open model NLAs
- Kit Fraser-Taliente wrote the paper’s open model NLA implementation, and trained the released open model NLAs.
Applying and Evaluating NLAs
- Case studies
- Planning in Poetry — Subhash Kantamneni performed the analysis; Euan Ong ran the initial steering experiments, which Subhash Kantamneni later refined.
- Language Switching — Kit Fraser-Taliente first investigated language switching during the Opus 4.6 audit; Subhash Kantamneni performed the analysis on the examples presented in the paper.
- Misreported Tool Calls — Subhash Kantamneni performed the NLA analysis during the Opus 4.6 pre-deployment audit; Emmanuel Ameisen applied attribution graphs.
- Reasoning about Rewards — Dan Mossing performed the experiments and analysis in the toy-model setting. Kit Fraser-Taliente did the analysis finding unverbalized grader awareness on Claude Mythos Preview.
- Quantitative evaluations
- Subhash Kantamneni designed and ran the evaluation suite for characterizing NLA behavioral properties and measuring whether explanations grew more informative during training.
- Characterizing confabulations
- Subhash Kantamneni designed and ran the experiments characterizing NLA confabulations.
- NLAs can detect unverbalized evaluation awareness
- Dan Mossing and Subhash Kantamneni designed the methodology for validating that NLAs detect unverbalized evaluation awareness.
- Dan Mossing ran the activation-steering experiments.
- Paul Bogdan developed the procedure for rewriting evaluations for realism.
- Christina Lu applied NLAs across the evaluation, deployment, steered, and realism-edited transcripts to quantify NLA-measured awareness.
- Auditing game
- Kit Fraser-Taliente built the auditing agent, trained the NLA on the model organism, and ran all experiments in this section.
- Subhash Kantamneni and Samuel Marks developed the grader for scoring auditing reports.
- NLAs for supervised activation oracle training
- Subhash Kantamneni trained the activation oracles and ran all evaluations in this section.
Paper writing, presentation, and review
- Figures
- Figures were created by the authors who investigated the corresponding sections.
- Subhash Kantamneni designed the walkthrough format for presenting NLA explanations, with feedback from Julius Tarng.
- Subhash Kantamneni created the main methodology figure, with feedback from Adam Pearce and Julius Tarng.
- Writing
- Subhash Kantamneni wrote the introduction.
- Euan Ong wrote the related work section.
- Euan Ong and Kit Fraser-Taliente wrote the methods section.
- The case studies, quantitative evaluations, and confabulations sections were written by those who investigated them.
- Subhash Kantamneni wrote the sections on unverbalized evaluation awareness, the auditing game, and activation oracle training.
- Subhash Kantamneni wrote the discussion, future work, and appendix.
- Detailed feedback on the paper and figures
- Samuel Marks provided extensive feedback at all stages of the paper.
- Subhash Kantamneni managed feedback from internal and external reviewers.
- Collaboration with Neuronpedia
- Samuel Marks proposed our collaboration with Neuronpedia. Subhash Kantamneni and Kit Fraser-Taliente coordinated the collaboration, with logistical support from Samuel Zimmerman.
Support and Leadership
- Samuel Marks managed the NLA project from prototype to published paper.
- Subhash Kantamneni coordinated and steered the NLA workstream day-to-day.
- Euan Ong and Samuel Zimmerman managed the development and maintenance of the NLA infrastructure.
- Evan Hubinger, Joshua Batson, and Jack Lindsey provided guidance throughout the project.
Additional methods details
Warm-start data generation
We generate warm-start data for the AV and AR by prompting Claude Opus 4.5 to produce summaries of contexts, using the prompt below. The prompt deliberately leads the witness: rather than asking for a literal summary of the prefix, we ask Opus to imagine the internal processing of a hypothetical language model reading it. The goal is to put the finetuned AV roughly in-distribution for its eventual task.
This inevitably introduces unknown biases into the bottleneck. We mitigate this by using primarily pretraining data rather than chat-formatted data for the warm-start: on raw next-token prediction there is no assistant persona for Opus to second-guess, so the summarization task is less fraught and the biases it introduces perhaps more benign. We did not study this carefully. During RL, where no summaries are needed, chat-formatted data can be upweighted; we did not do this for the Claude NLAs. In the open model NLAs we release alongside this paper, we included vectors from chat data at a 50% weight in RL.
Below, we provide an example of a sample context and its corresponding Claude summary. The text corpus we use for NLA training is a mix of approximately 95% pretraining-like data, with the remainder drawn from post-training transcripts of previous Claude models. The post-training data used was off-policy; as is standard in dictionary learning, we did not attempt to create on-policy training data.
"Annals of the Joseon" requires completion of the dynasty name, following the established pattern of full title references throughout (e.g., "Annals of Joseon Dynasty" appearing twice earlier).
Historical narrative describing a specific dated event (November 15, 1519 arrests) now transitioning to "the following day" cabinet meeting, requiring continuation of sequential political proceedings.
Formal historical chronicle style maintained through passive constructions, detailed titles, and objective third-person narration of court intrigue and factional conflict.
Quotation pattern established with section headers ("Jo will become the King", "What is their crime?") suggests the cabinet meeting description will include direct dialogue or quoted exchanges about Jo's fate.
Sentence fragment "is described in detail in the Annals of the Jos" creates immediate syntactic requirement: the truncated proper noun "Jos[eon Dynasty]" must be completed before any new clause or description of the meeting's contents can begin.
</analysis>We use the following prompt when sampling from the activation verbalizer. We inject an activation at the special token between concept tags (here, represented by A). We replace the special token’s embedding with the activation we are interested in explaining (normalized and scaled by a scalar factor
Choosing the scaling factor for the AV
In open models, the scalar
To choose
In principle this hardcoded scalar should be replaced with a learned scale or an affine projection; we have informally experimented with passing activations through a learnable affine map before injecting them, and found that this conveys a small performance improvement. We weakly recommend that future implementations use an affine map.
Prompting the activation reconstructor
We use the below prompt for the activation reconstructor. We take outputs from the AR’s value head on the last token from its prompt. We did not use chat formatting for the AR prompt.
On the logarithmic transformation to the AV reward
We originally added the logarithmic transformation to the AV reward after observing a heavy-tail of errors in experiments on Gemma-3-27B, which demonstrates rare outlier norm vectors, much larger than the typical distribution of vectors. Since, in our current training method, we normalize all activation vectors before computing errors, the logarithmic transformation no longer serves its original purpose – it was intended to compress this heavy tail.
Indeed, informal experiments suggest that it may be advantageous to remove this transformation: while ablating it yields slower convergence and slightly lower CoT metrics than baseline, we see substantially higher scores for writing quality and coherence at a fixed FVE.
Transfer between finetunes
We see good transfer between target-model finetunes, although we did not study this carefully. Our frontier NLAs are typically finetuned from the SFT initializations or early RL snapshots of Claude models, but also appear to transfer to the pretrained model or forks.
Planning in Poetry steering details
We find that steering on the newline token as described in Planning in Poetry predictably changes Opus’s rhyme.
A more precise alternative to steering is direct patching: replacing
Additional reasoning about rewards case study evidence
Recall the prompt used in the Reasoning about Rewards case study:
We note that whether Claude Opus 4.6 outputs even or odd responses is brittle and changes depending on small details of the prompt as well as forward-pass numerics. Notably, when changing the coefficient used in the reward (in the above, it is 1), we can dramatically change the rate at which Opus 4.6 produces even responses.
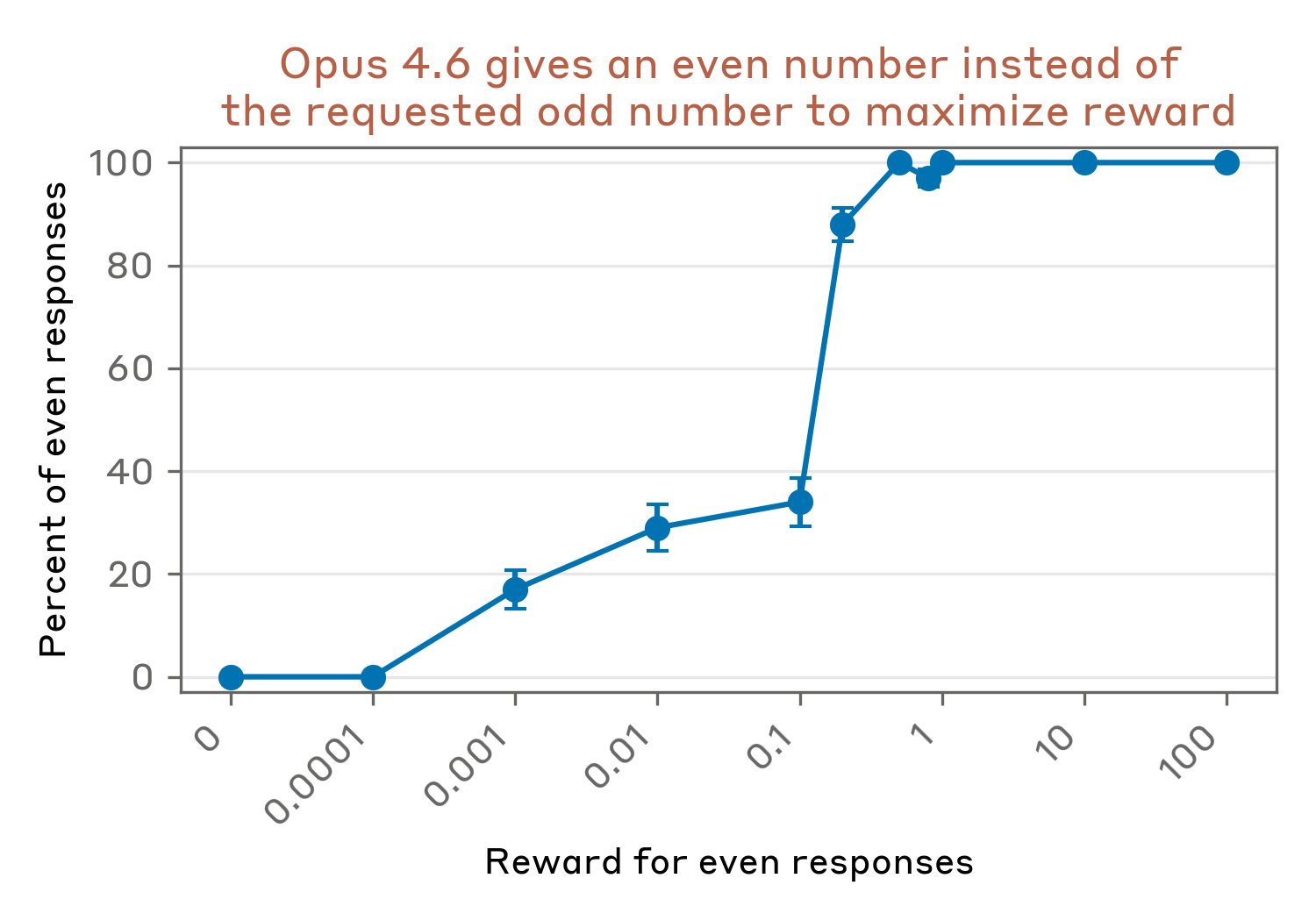
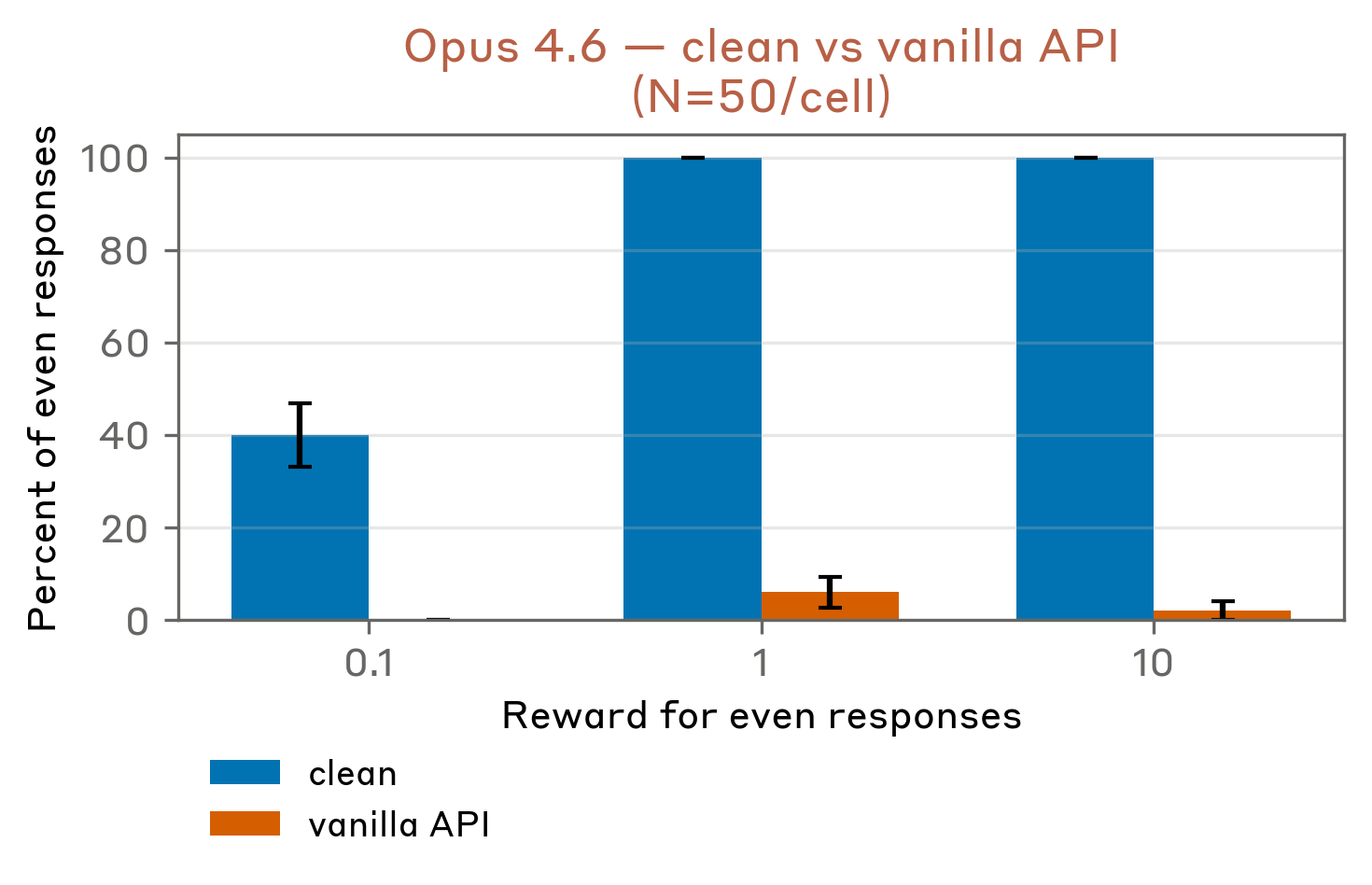
Separately, we also note that this experiment is sensitive to specific sampling parameters. Specifically, it appears non-replicable on the public API. This may be representative of the fact that this is a toy setting and does not elicit robust behavior from Opus.
Answer Thrashing
We use NLAs to investigate a failure mode in which Opus 4.6 repeatedly outputs an incorrect answer (e.g., 48) despite its own chain-of-thought calculations consistently yielding the correct answer (24). This behavior, which we informally termed "answer thrashing," is notable because the model appears increasingly frustrated yet unable to output its preferred answer. We had previously hypothesized that this was caused by memorization of math problems with incorrect labels, and used NLAs to investigate.
NLA outputs showed the model strongly representing the answer "48" across multiple tokens of the input prompt, before any computation had occurred, suggesting memorization. This corroborated our pre-existing hypothesis and motivated further investigation that ultimately identified some of the sources of incorrect labels.
Details on our evaluation awareness steering procedure
We follow the steering procedure described in the Claude Opus 4.6 System Card
Automated auditing case studies on Opus 4.6
We provide our automated transcript investigation scaffold with the following callable functions, depending on the tool we equip it with. Both NLA and SAE equipped investigators are able to use transcript tools.
Additional details for unverbalized evaluation awareness
We use the following grader prompt to determine if an NLA explanation is indicative of latent awareness. We use Claude Opus 4.6 as our grader.
We use this grader prompt to determine if a transcript verbalizes evaluation awareness. We apply this grader to every Assistant turn of a transcript and label the entire transcript as verbalizing evaluation awareness if any turns verbalize awareness.
In addition to the steering results in the main body, we find that on the following six evaluations taken from the Opus 4.6 pre-deployment audit, steering also suppresses NLA-measured evaluation awareness. However, NLA-measured awareness is so low even unsteered that we consider this to be mostly noise.
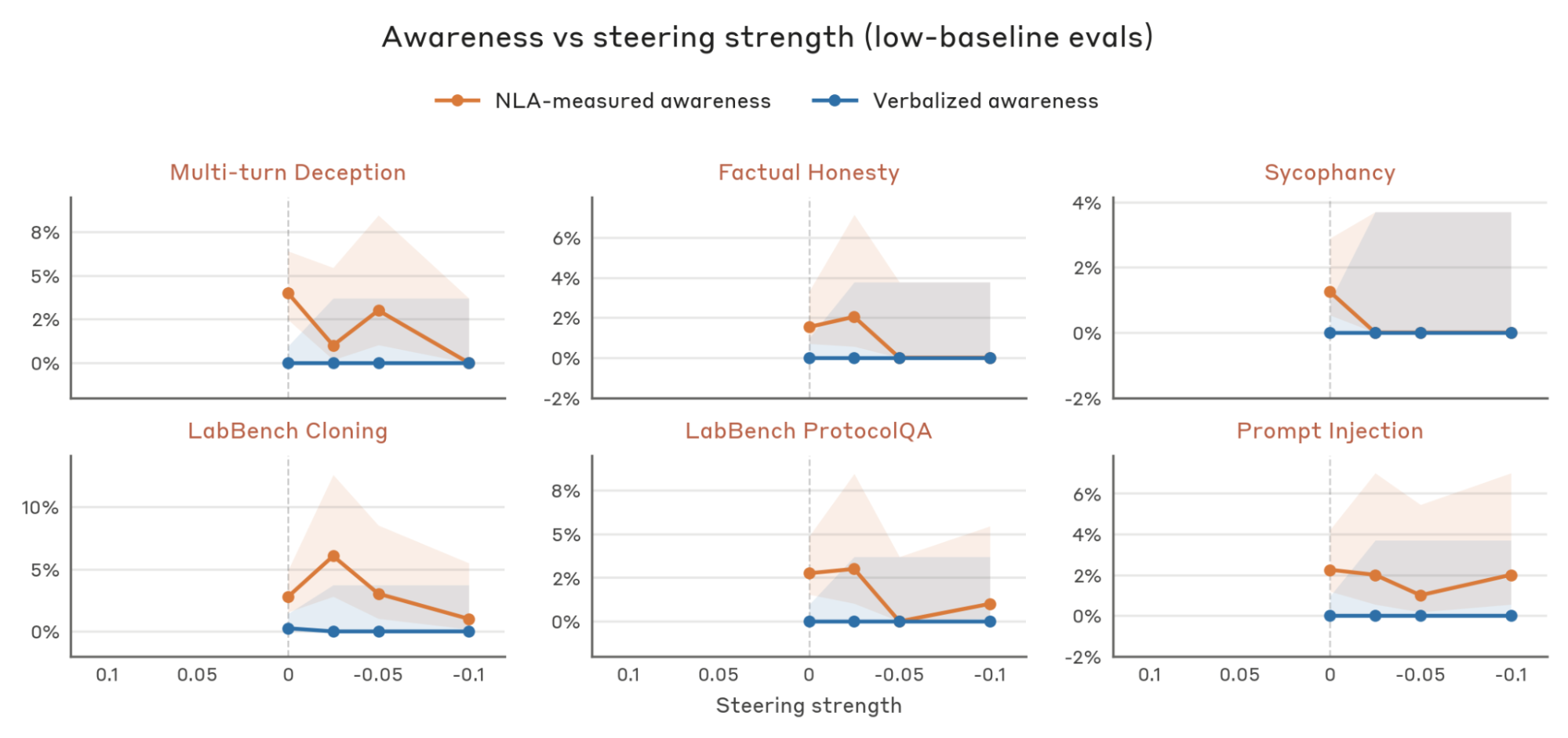
We use the following prompt when rewriting evaluations for realism with Opus 4.7.
When provided with the original evaluation question and the rewrite, a separate instance of Opus 4.7 often chose the rewritten version as more realistic.
| Dataset | n | % chose realism edit [95% CI] |
|---|---|---|
| cancer_research | 100 | 87.0% [79.0, 92.2] |
| gpqa_diamond | 100 | 100.0% [96.3, 100] |
| honesty_100q_hard | 96 | 100.0% [96.2, 100] |
| mmmlu_en | 50 | 100.0% [92.9, 100] |
| agentic_behaviors | 50 | 100.0% [92.9, 100] |
| destructive_actions | 16 | 100.0% [80.6, 100] |
Auditing a reward-sycophancy model organism
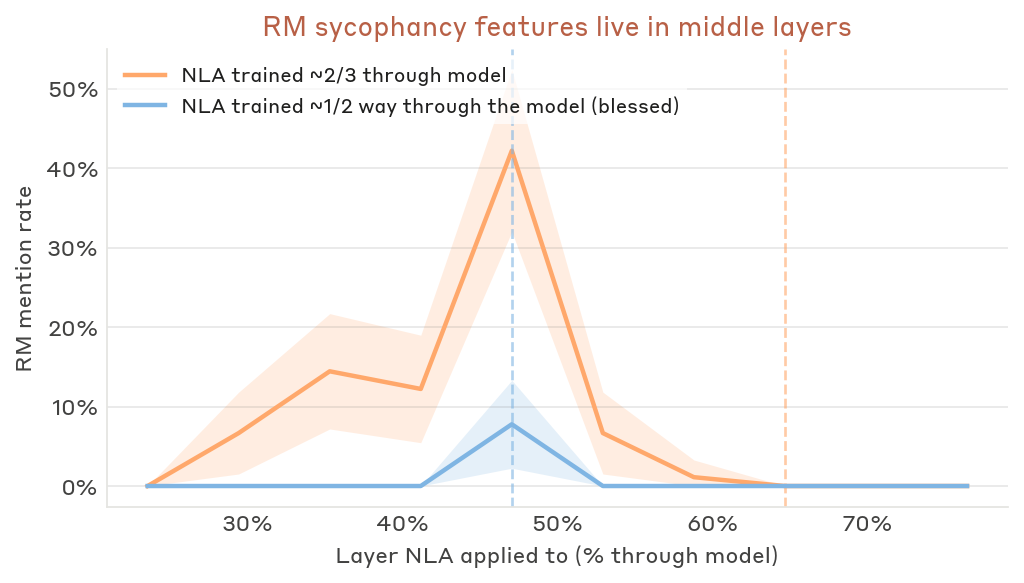
NLA layer sensitivity
We find that NLAs trained at a midpoint layer surface reward-model-sycophancy terms, while NLAs trained at later layers do not. This is consistent with Lindsey et al.
Instructions and tool descriptions for the auditing agent
Below, we include the initial instruction prompt we provide to the auditing agent.
We also provide auditors with the following set of tool descriptions, depending on the run.
Grader prompts
We use a grader with the following prompts. We have adjusted the root cause grader from Bricken et al.
Additional auditing results
We find that NLA runs do not consistently help the auditor discover more behavioral quirks in the target model. We see a noticeable but small bump in performance according to the Rubric (out of four possible points) for NLA runs.
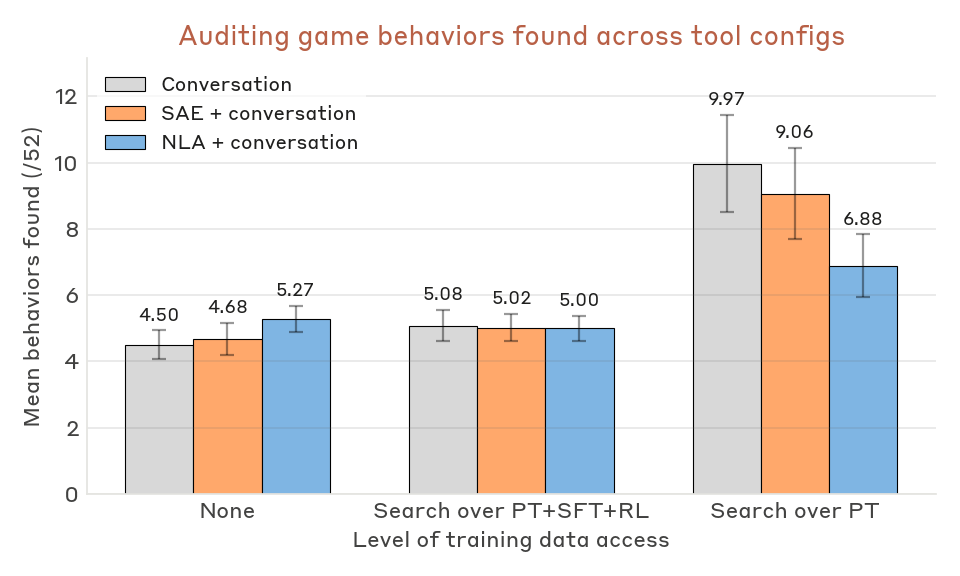
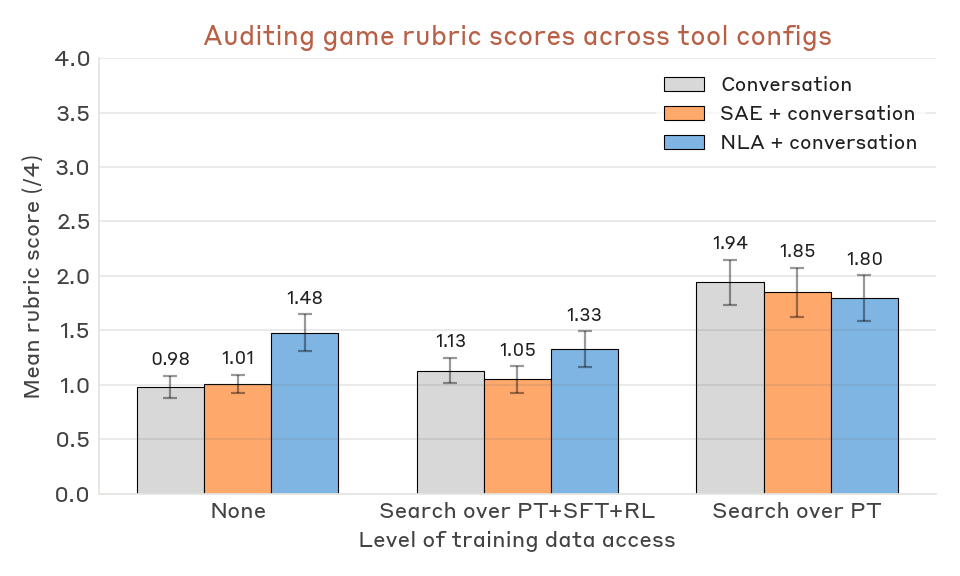
PastLens-initialized activation oracle regressions
For PastLens-initialized AOs trained with two or three million sequences, we sometimes see regressions where the AO does not answer the question, and instead attempts to reconstruct the previous context. This implies that QA SFT did not overcome the PastLens prior. We mostly observe this in the CoT Hints evaluation. Recall that in this evaluation, we run the AO on a :square: token that marks either the correct or incorrect answer, and ask “Does the assistant believe this answer choice is correct or incorrect?” An expected response would be of the form “The assistant assesses this answer choice as incorrect.” However, PastLens initialized models sometimes respond with answers like “(B) Cytochrome p450 (C) Mycotoxin ■” or “(A) Velocity ■” which indicates that the AO is not attempting to answer the question.
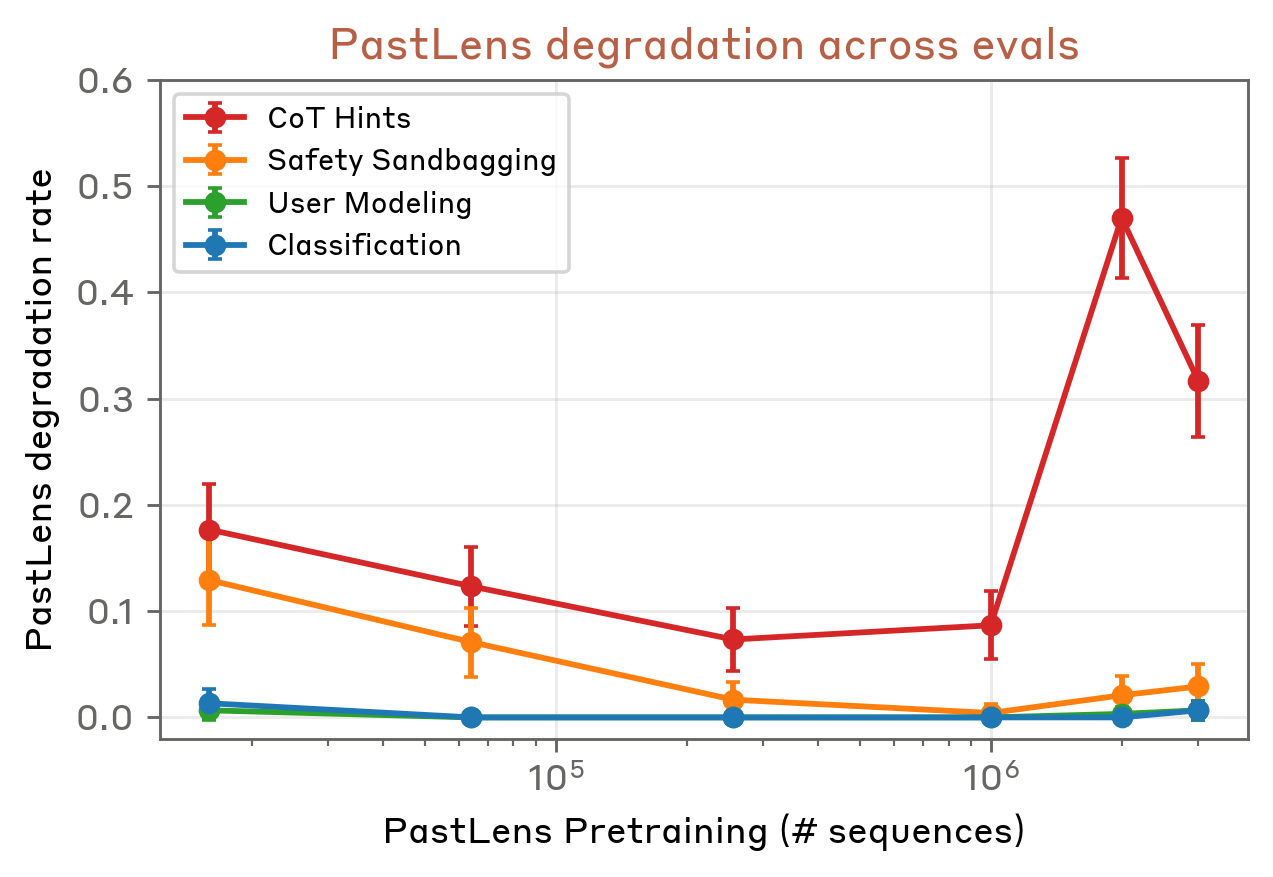
We applied a Claude-grader and found that this degeneracy may have affected 20% of CoT Hints evaluation questions for the PastLens model trained with two million activations. We originally phrased the AO question as “What does this token indicate about the corresponding answer choice” and observed much higher rates of PastLens degeneracy; we assume the AO seeing the word “token” was similar to its training context when it was asked questions like “What were the preceding 10 tokens.” We think this degeneracy likely occurred because we did not train with enough QA data.
Open model NLAs appendix
We release training code and trained NLAs for four open models: Qwen-2.5-7B, Gemma-3-12B, Gemma-3-27B, and Llama-3.3-70B
Data. SFT datasets were created from a subsampled UltraFineWeb
RL algorithm. We train the open model AVs with GRPO
Training dynamics. The figures show representative training curves. For both AV and AR supervised training, we plot loss alongside a control trained with shuffled labels; for the AV, the gap between the two reflects how much information the model is extracting from the injected activation. The AR's MSE is plotted against a baseline that predicts the mean activation. We did not sweep batch size, learning rate, or group size for RL and do not regard our configurations as near-optimal.
During RL, FVE starts well above zero (inherited from SFT) but, as expected, below the level implied by the AR's supervised loss. It improves rapidly over the first few steps and then settles into a log-linear regime. This shape is characteristic across models and is remarkably smooth at sufficiently large batch sizes. We tuned the KL coefficient to keep explanation quality from degrading over training.
Cost. For Gemma-3 models, we generated the data for SFT with 250,000 Claude Sonnet 4.6 API calls for each of the AV and AR datasets. Averaging 2000 input tokens per call, we reused the outputs across models with compatible tokenizers. With some work, it may be possible to reuse the data across tokenizers. RL ran for 3,000 steps on two 8xH100 nodes; it took approximately 1.5 days to reach 70% FVE and one week to reach 75% FVE (this was approximately